迭代器模式
定义
提供一个方法顺序·访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示。
举例
在我看起来迭代器出现的原因其实很简单,也很符合我们的单一职责原则。这个模式出现的原因,就是为了去解决一个数据结构中可能存在的数据遍历问题。
搓过数据结构的都知道,你只搓出数据的底层表示是远远不够的,你还需要提供一个或多个方法去进行这些个数据的查找,遍历等。在C++中的stl库中也是如此,所有的数据类型中都给我们提供了一系列的迭代器接口供我们去对数据进行查找和遍历等。而这些个查找和遍历所应用的设计模式,就是迭代器模式。
总的来说,一个迭代器模式的出现就是一个为了方便用户去进行使用的初衷,通过对于一个数据结构提供一个查询的接口,去避免用户自己去进行底层数据的遍历。
这是一个很朴素的哲学,一路过来,我们都尽量避免我们的底层数据能与用户直接接触,因为这种接触是不可控的,我们无法控制这种交由用户自己处理的行为是否会出现什么问题。因此,为了程序的稳定,同时也为了使我们的程序更加的智能,我们通常需要去为我们设计的东西添加尽可能多的接口而不是去暴露我们的数据。而且,你应该也有体会,当现有的就存在一些简便的方法时,你一般不会去在现有的方法上再去设计一个功能相似的方法,这也是设计模式的一种哲学。
补充的哲学思考
- 接口即契约:
提供一个迭代器接口,就是在告诉用户“这是访问数据的唯一正确方式”,从而规范了用户的行为。这种契约精神不仅使程序更稳定,也为团队协作和代码复用带来了极大的便利。 - 从用户角度出发:
当你设计一个程序时,始终要考虑用户的使用体验。迭代器模式的核心出发点就是“如何让用户以最简单的方式访问数据”,这体现了优秀设计的以人为本。 - 避免重复发明轮子:
一般来首现有的迭代器接口已经很好地解决了数据访问问题,因此通常不需要重复设计功能相似的接口。这种“站在巨人肩膀上”的思维不仅高效,也能让你的设计更加稳健。
对于迭代器模式存在的意义,我们已经基本了解了,接下来我们直接进入对应的UML类图和代码实现吧
UML类图
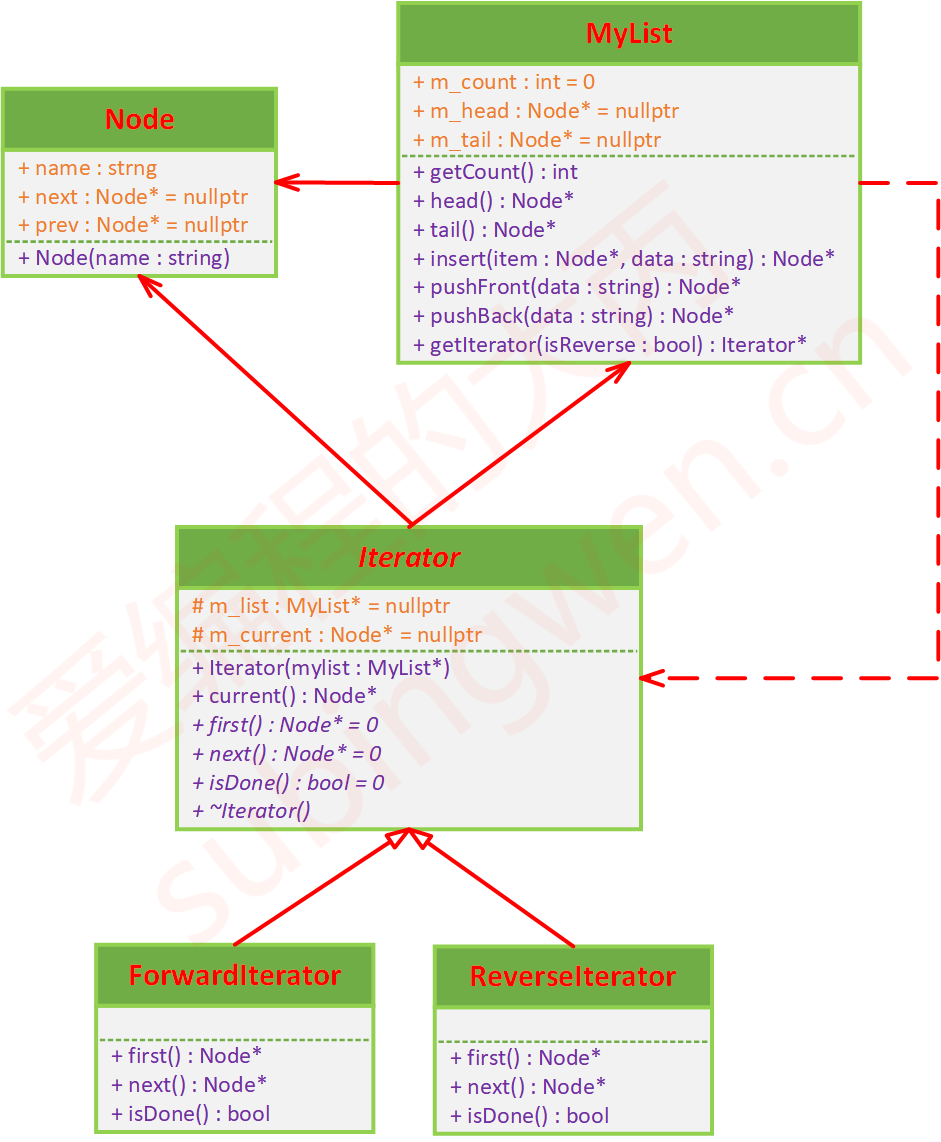
借用一个UML类图进行分析
对于一个迭代器模式,我们首先需要知道的是,其根本上是为了对于一个数据结构进行排序查找等方法的提供的。因此,我们需要一个数据结构作为我们的底子。在这里的UML类图中,我们使用一个双向链表作为示例。
Node类
做过数据结构的就知道这个是用来干嘛的了,这里就不再进行赘述了
MyList类
这个类就是我们这个迭代器模式中的服务对象,就是我们的具体的数据结构。可以看到在这个类中,我们包含了一个计数用于标识这个数据结构中插入元素的数量,该包含了一个用户头结点和尾节点的指针用于这个链表的标识。
接下来看到这个类中的函数,其中很多都很常见,就不再赘述,主要看到这里的getIterator函数,这个函数返回一个指针,这个函数返回一个指针,这个指针指向一个迭代器。也就是说,这个函数就是一个我们进行迭代器调用的接口,通过这个接口,我们可以实现迭代器方法的调用。
当然,这种你爹带起的调用其实见仁见智,我觉得还存在一种调用方法就是直接在这个类中去进行一个迭代器的声明,利用组合或者聚合的关系进行构造,也可能再利用一种外观模式,将我们的这个数据模块和排序模块给封装起来实现我们的功能,当然,这里只是提出一种方法,具体的实现可以多种,虽然我自己也没搓过几个,见仁见智吧。在这里说这些知识我思维的一些发散罢了。
Iterator类
这个类就是我们的迭代器类,这个类在设计中准备负责的功能就是实现我们的排序模块。可以看到,在这个类的成员中,包含了一个我们自己设计的一个链表,这个就是我们这个迭代器中赖以实现排序功能的基础。这里就不再赘述。另一个成员是一个用于标识当前指向的节点的地址,也没有什么分析的价值,看到成员函数吧。
在这里的成员函数中,大多都是一些抽象虚函数,由这些形成了多态体系,这里也不再多说,总的来说,这里的迭代器的组成还是相对来说比较简单的,不需要多么深入的剖析。
还可以看到,在这里的抽象基类底下,还有着几个相对独立的子类,这里分别是一种顺序遍历和逆序遍历的方法,这里也是对前面多态特性的一种补充,也没什么好说的。
总的来说,迭代器模式的UML类图相对来说比较简单,主要是看代码自己搓一遍熟悉流程,等到之后自己项目中去用一遍也就差不多了。
代码实例
进入代码分析之前,我们需要对一个C++性质进行一定的分析,其实我也有点忘了,之前学过就没有再拿起来用过。
模版特性简析
使用template
一个模版声明的作用域是有限的,其只会在其最近的一个作用域中生效。
这里使用GPT总结版,写的很清楚。
1. 模板的声明与定义
template <typename T> 声明的模板类型参数 T 的作用范围从声明开始,覆盖模板定义内的所有内容。例如:
1 | template <typename T> |
这里的 T 只在 MyClass 的定义内有效,离开 MyClass 后 T 不再有意义。
2. 嵌套作用域
如果模板参数声明出现在嵌套的作用域中(如嵌套类、成员函数等),模板参数的作用范围会受到进一步限制。例如:
1 | template <typename T> |
- 在
Outer的定义中,T是有效的。 - 在
func的定义中,U是有效的,但U的作用范围仅限于func的内部。
3. 局部模板参数的作用范围
局部模板参数的作用范围只限于其声明的具体位置。例如:
1 | template <typename T> |
在 innerFunction 中,U 是局部模板参数,其作用范围仅限于 innerFunction 的定义。
4.特殊注意:模板的作用范围与嵌套
在某些嵌套场景中,外层模板参数与内层作用域可能会产生冲突。例如:
1 | template <typename T> |
在 method 中,T 指的是方法的模板参数,而不是类 Container 的模板参数。这种情况下可能会导致混淆,需要注意命名的区分。
模版总结
template <typename T> 的作用范围确实是局部的,仅限于最近的声明和定义所在的作用域。如果有嵌套作用域,内层的模板参数会遮蔽外层的模板参数。这种规则确保了模板的灵活性,同时也要求在设计模板时小心命名冲突的问题。
有了这个,我们可以来进行我们代码的分析了,启动!!!!!
通用迭代器类
1 | template <typename T> |
首先可以看到,我们使用一个模版来进行我们结构体Node的创建,这就使得我们最后的结构体基本能够兼容所有的基本数据类型,至于负责数据类型,可能还需要后续的更多调整。
额外多说一嘴,这里的结构体使用了构造函数,需要注意的是,这是cpp中的结构体有的特性,在c中是不存在的。
接下来看到我们的迭代器类,可以看到,我们的迭代器类也是使用了一个模版,在这个模版类中,我们还使用了一个模版结构体。这种嵌套需要我们在使用对应的嵌套结构体中去指定对应的类型,这里也是如此,通过将Node的类型指定为自身的模版T实现了一种模版范围的衍生,提高了扩展性。
接下来看到几个基类函数,这里就没有考虑去进行功能的扩展了,需要的话可以把这个类重新设计为一个ABC类再进行对应的设计,这里就不再展开了。可以看到,在这些个类方法中,提供了系列方法用于一些元素位置的查找,这里也不赘述,直接跳过。
具体的数据结构类
1 | // 链表实现 |
对于这个十分简陋的链表,我其实没什么可说的,唯一需要注意一点的就是我们这里的链表插入使用的是一个头插法的插入规则。那几个想说的放在这里又不太合适,我们直接看接下来的测试程序吧。
测试
1 | int main() { |
复用分析
这个其实也没有什么好说的,但是你看到的时候可能会为这种设计感到疑惑,就是说为什么要这么写。首先我们先来明确一下,在这段代码中的复用,指的是对于迭代器代码的复用,而不是对于迭代器这个类的复用。
理论上,你当然可以设计一些东西使得一个迭代器能够被多个类所使用,但是这样会存在一个问题,最直接的就是切换的问题,如果你来回的切换使用的对象而且你还需要保留上一次使用的记录,这会是非常麻烦的。再者,一个迭代器类被多个类所使用,如果不对呀迭代器进行严格的设计的话,这个迭代器类将会是线程危险的。
总的来说,为了避免总总的问题,我们的没一个迭代器,通常都是与一个对应的数据模块类所对应的,这样能减少很多的一个问题,而且由于迭代器类在设计上通常并不会有很多的类成员,大多都是一些api方法,所以这种开销是可以接受的。
规范
在这段测试程序中,我们可以看到,这几个都是使用了相同的方法名,这样一看过去,我们其实就能够简单的理解这类函数存在的一些通用方法,这其实就减轻了我们的学习负担,就比如我们的stl库,当我们了解了其中的一个之后,我们去了解其他的类,其实发现他们都大差不差,很容易上手。而这里就是我们迭代器类,或者说,编程规范的一种优势所在,通过规范的编程来降低用户学习使用对应的api的难度。
总结
总的看下来,迭代器模式其实没有什么好说的,主要就是我们如何去设计一个迭代器,一个数据模块中对于一个迭代器如何使用,用于如何使用数据结构提供的接口和在这之下的我们怎么去设计对应的数据结构下的数据模块和迭代器模块的配合。
这总的来说主要是一种实战的技能,可能会在之后去浅浅设计一个自己的vector类来进行熟悉吧。