期望与现实
在本文中,我将基于个人在学习过程中遇到的一个具体痛点来进行复盘,探讨在Agent开发中最容易陷入的“过度工程化”陷阱。
初始需求
在初始设计阶段,我的需求其实很简单:我想设计一个能够深度思考用户输入问题的Agent。顺着目前主流教程的思路,我理所当然地采用了 Plan-and-Execute(计划与执行) 架构。基础思路很清晰:首先是一个 Planner 负责将用户问题拆解为细致的子任务;接着由 ProcessAgent 接收规划并执行;最后由 SummarizerAgent 汇总信息并给出最终回答。
借助大模型的辅助,编码和Review进行得非常顺利,代码结构也极其优雅。但是,当系统真正跑起来时,现实却给我浇了一盆冷水。
以一个非常基础的网络问题为例:“请分析一下什么是TCP中的粘包拆包问题以及常见的解决方案”。我对比了原生简单的 API Call 和我这套复杂架构的输出结果。令人沮丧的是,复杂架构不仅没有给出更优秀的回答,其耗时、内存占用、特别是 Token 消耗都呈现出了爆炸性的增长。
明明我上了一个教程中的“优雅”架构,为什么效果反而更差了?带着这个疑问,我开始重新审视整个Agent的底层逻辑。
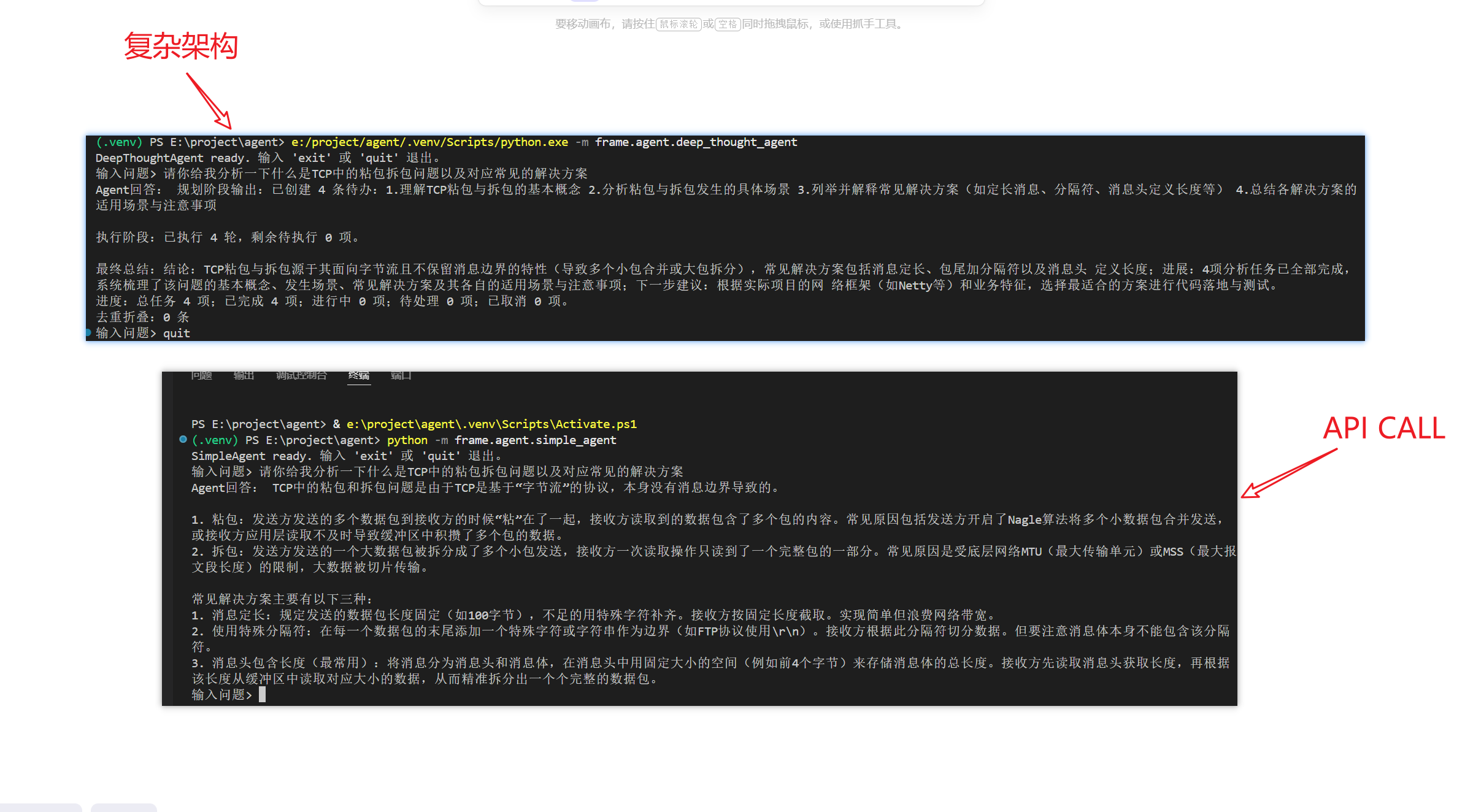
为此,我与LLM反复探讨了这个问题。由此有了一定的感触。
复杂架构的代价:什么是真正的“架构错配”?
目前市面上绝大多数的教程,都在大力推崇 ReAct、Plan-and-Execute、Reflection 等范式,强调它们如何让“推理使行动更具目的性”。这些高度抽象的总结本身没有错,但它们往往没有说架构的背后隐藏了一个残酷的工程现实:任何复杂架构的引入,都伴随着高昂的技术债。
在这套 Plan-and-Execute 架构下处理“TCP粘包”问题,究竟发生了什么?我认为,这本质上是一种严重的“架构错配”。具体而言,这种错配可以拆解为三个维度:
- 计算错配(Token与延迟爆炸): 为了解决一个简单问题,系统被强制拉长了战线。多次的 LLM 交互和复杂的 Prompt 模板,导致 Token 消耗急剧上升,网络通信和 IO 成本也随之水涨船高。
- 信息错配(无信息增益): 引入架构的核心目的是为了获取更高的准确度。但在简单定义的问答中,Planner 将问题拆碎不仅没有提供任何“信息增益”,反而摊薄了 LLM 的注意力,导致最终生成的连贯性和聚焦度下降。
- 控制错配(流程冗余): 简单问题的控制流完全可以在 LLM 内部的单次 Forward 中自洽完成。强行由外部 Agent 系统来接管控制流,属于典型的“杀鸡用牛刀”。
用一句话来概括:我们引入的系统控制复杂度,远远大于了问题本身的复杂度。
重新审视需求:问题分级模型
为什么我会犯这种错配的失误?根本原因在于“手里拿着锤子,看什么都是钉子”。我并没有从实际需求出发,而是盲目假设所有输入都需要被“拆解”。

为了避免这种错配,在设计 Agent 系统时,我们首先应该建立一个“问题分级模型”:
- Level 1:单跳问题(无需拆解)。例如事实查询、名词解释(如我的TCP问题)、简单翻译。这类问题最佳的解法就是 Direct QA,直接调用基础大模型。
- Level 2:多步推理(可能需要拆解)。例如简单的逻辑推导或多表数据对比,可能需要思维链(CoT)或轻量级的交互。
- Level 3:开放任务(必须依赖 Agent)。例如编写一个包含前后端的完整小应用,或者进行深度的全网行业研报调研。这类任务流程长、依赖多。
我的“TCP粘包”问题是一个标准的 Level 1 问题,而我却给它套上了解决 Level 3 任务的重型铠甲,自然举步维艰。
破局之道与反面验证
那么,遇到上述问题该怎么破局?
既然系统需要应对不同层级的复杂度,我们的架构第一层就不应该直接是 Planner,而应该是一个轻量级的 Router(意图路由Agent)。由 Router 来判断用户问题的 Level:如果是单跳问题,直接路由给基础模型快速响应;如果判定为复杂的开放任务,再拉起 Plan-and-Execute 链路进行拆解。
反过来思考,Plan-and-Execute 在什么场景下才是真正必要的? 只有当问题跨越了单次上下文窗口的认知极限时,它才大放异彩。例如:
- 多文档深度检索: 需要横跨数十万字文档提取并综合交叉信息。
- 长链路工具调用: 需要先查数据库,再调用外部API计算,最后生成报表。
- 长任务分解: 比如生成一个拥有几十个文件的完整代码仓库。 在这些场景下,Planner 提供的规划和上下文隔离,能够产生实打实的“有效信息增益”。
总结
这次实践给我上了一堂深刻的工程课:在 Agent 时代,并不存在绝对完美或包治百病的架构,我们真正要追求的,是架构能否在当前问题中产生“有效信息增益”。
任何一个优雅的框架,都是前人在复杂的业务场景中摸爬滚打、趟过无数浑水后总结出来的。我们不能仅仅因为教程里说它好,就盲目推崇它的泛用性。
抽象点来说,还是那句老话:“实践是检验真理的唯一标准”。在大家都争相往前冲的 AI 浪潮里,作为开发者的我们更应该沉下心来,去踩一踩前人踩过的坑。只有切实经历了从“滥用”到“错配”,再到“优化”的痛苦,我们才能真正掌握:一个架构究竟该在什么时候用,以及该怎么用。