BPM优化
本文借15445的爬Rank的契机,来进行对于BPM设计上的优化,进而来分析如何优化并发的设计。这是一次相当有趣的设计体验。其中所需要的经历相当的多,同时也收获很多。
动机
在初始阶段,为了能够Pass掉所有的测试用例,我考虑使用一个粗暴的大粒度锁(BPM级别的锁)来保护一系列状态。最后经过一系列调整确实能够跑通Gradescope上的所有测试点,但是最后的Rank不甚理想(如图1)。
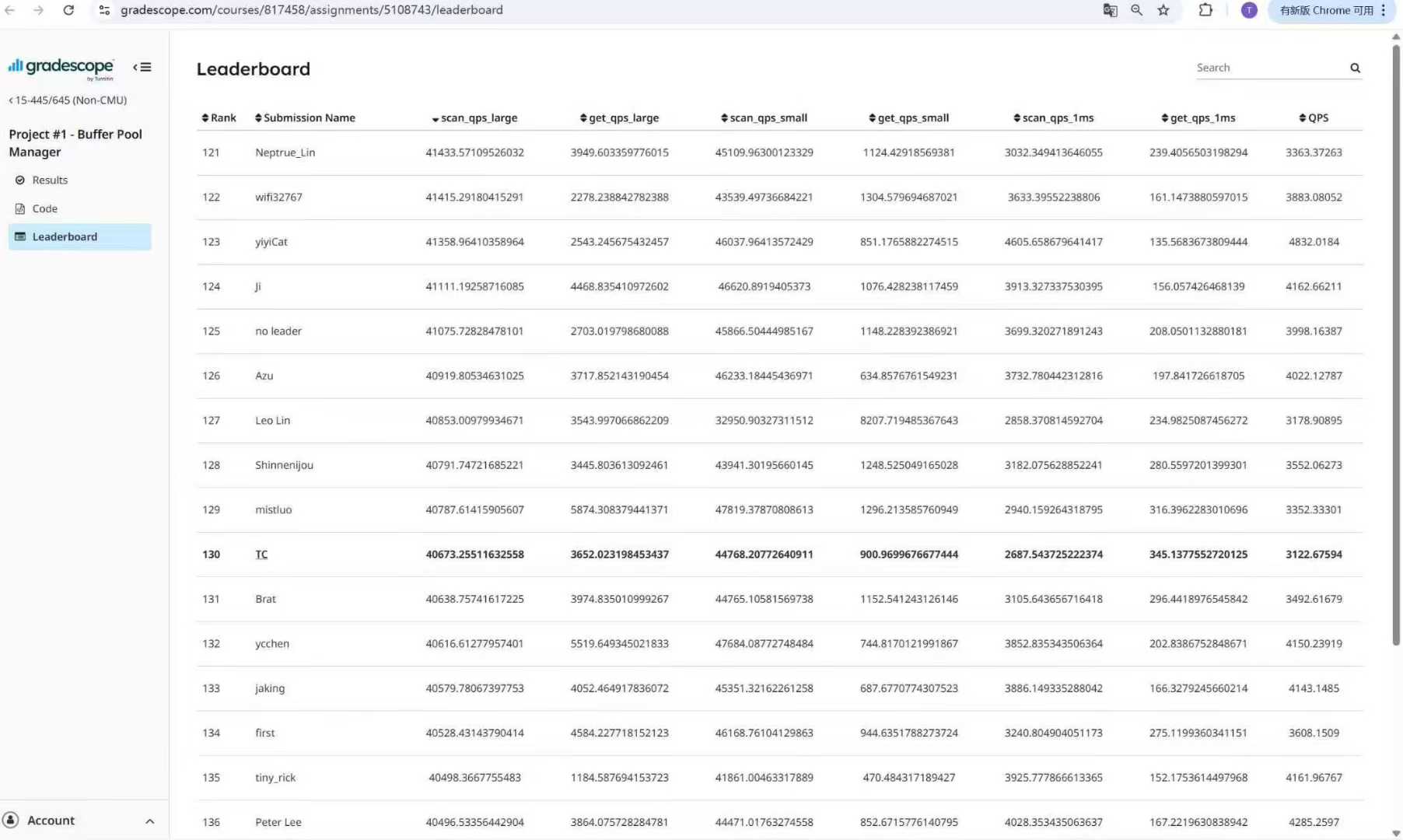
为了获取更高的Rank(至少要到前100吧),我需要来对于现有的设计来进行一次全面的优化。为此,我们需要放弃使用一个全局锁来进行封锁,而改用一些更加高级的策略来进行优化,这就引出了我们本次所需要分析的内容:如何在缩小锁粒度的同时保证程序本身的正确性。
思路
对于QBS的优化,在我认为第一步实际上不是优化锁的粒度。因为其实很易懂的一点,如果我们优化的部分不是瓶颈,那么在这方面再做如何的优化,对应的提升的效果也不会很好。对于我来说,我的第一次优化相对来说是较容易的,或者说,由于有较为明显的缺陷。就是我在一个全局锁内阻塞的执行了全部的状态改变+顺序阻塞IO处理,而这无论如何是不可接受的。故我专门针对这一点进行了优化。首先的思路是将对应的IO执行移出全局锁的临界区并保证整体逻辑的不改变。
我们应该如何来看待并发?对于我来说,并发是多个执行流的同时运行。我们需要保证这多个执行流之间的互不干扰吗?这是一种保证并发安全的做法,但是这种做法是最初级的做法,通过在各个执行流的起始点来限制串行就能够实现这点,不过正如你所想,这往往是不可接受的。因为,这太慢了。这相当于是将并发的操作处理为了单线程的操作,而且还附带上了一系列的上下文切换损耗以及空转等。相当的不优雅,而为了能够优化这种场景,我们需要换一种视角来看待并发,不能够以一种互斥的角度来看待并发。对于我现在来说,应该以一种可预测,可处理的观点来看待并发。我期望的并发是我能够在一个执行流观测到另外一个执行流的行为,并且当前执行流能够通过观测到的行为来实现协调,进而实现整体的执行流的正确有序推进。严格来说,前面所说的全局锁是这里的一种方法,我们这里不过是稍微往深处走一走来了解。
对于全局锁来说,我们所期望的是什么?我们期望的是我们进入该锁的临界区后,所有我们需要的状态都不发生改变。对于本个执行流来说,这实际上就是确定化了本次要使用的内容,所以后续的操作能够保证基于这个快照的状态来操作而不必担心在这中途发生一些“奇怪”的事情。那么,我们期望的细粒度锁会导致什么呢?顾名思义,由于锁的粒度变细了,所以其中势必会存在一些无法被确定化的状态,就比如如果我们将IO移出临界区,那么IO以及后续的操作都是一个不确定或者说UNKNOWN的。我们不可能基于一个UNKNOWN的状态来做任何操作。但是为了保证并发本身,我们又不能允许这种情况的发生,所以我们需要对于其进行弥补。而这种弥补操作,则遍布了我们本次所需要来进行优化的整个步骤。任何操作都是有代价的,对于并发的本身更是如此,对于任何一处从临界区中移动出来的操作,我们都需要详细考虑是否需要进行弥补,来保证我们并发执行流的正确推进。
对于这种“弥补”操作,对于我来说,有一种感触,其实际上是由俩部分所组成:不变式+协议。个人对于俩种的个人理解如下:
- 不变式(invarient): 哪些条件必须始终成立,哪些条件是不确定的。即,不能允许任何一个位于临界区外的点是完全不可预测的
- 协议(protocol): 当部分状态暂时不可用时,其他线程/协程应该如何做(等待、失败放回还是重试等)
通过对于这俩者的利用,我们能够将一些临界区外的行为进行确定化,而通过这种确定化,我们能够弥补将这些行为移出临界区的代价。而再次之后,我们就能够再次评估将这些行为移出临界区所带来的代价以及收益。这就是围绕我们后续一系列操作的主线。
IO临界区
我们本次所需要优化的接口为GetFrameForPage。我们先回顾一下先前的设计中的该接口的行为会是什么。在先前的设计中,其会在函数执行过程中全程持有BPM的锁,而在所的临界区内部,其设计到了BPM本身部分状态的修改,对于LRUKReplacer策略类的记录,以及最重的IO操作。在这其中,其中优先处理的就是IO操作,其可能是来自一个被驱逐Frame的刷盘操作,也可能是来自一个新页的读写操作。这俩者相对都是重量级的操作,优化其能够得到的效益将会是最高的,我们接下来集中于这俩者的IO操作。
首先观察到这俩种IO操作的触发点,对于刷盘操作来说,其的触发点是当一次GetFrame时当前页既不在内存中,也无现有的空闲帧可复用时,需要手动驱逐一个帧来复用且该帧为脏页时的操作。而对于读盘操作来说,其的触发点是当一次GetFrame读到的页并非当前已有的页且该当前该帧已经非脏页时所需要的操作。
总的来说,我们需要处理这俩种可能的IO操作,需要将这俩种IO操作给移出由BPM所构造的临界区。我们接下来分析将这俩种操作移出临界区之后会导致的问题。
对于我来说,如果将这些IO操作每个都分析一遍来进行处理,那是不可接受的。我考虑抽离出其中的共性来分析。在我看来,其中的共性为一点,其都是Frame本身的IO操作以及整个GetFrame本身围绕的元素本身。故我的基本思路为直接从Frame本身来入手。对于Frame本身,我为其显式附加了一个状态变量FrameStatus status_。我想要做的是,在整个GetFrame函数中来建立起一个对于Frame的确定性状态机,通过将各个步骤涵盖住Frame本身。
对于FrameStatus ,我将其划分为三个基本状态FREE,READY,LOADING。这三个状态涵盖了我理解的Frame的状态。其中FREE代表当前的Frame是一个空闲状态,未被任何一方所使用,其中不承载任何数据,可直接被使用,list<frame_id_t> free_frames_中的所有frame都应该处于该状态。LOADING态的Frame是一个中间状态,该状态的Frame不应该长久存在,其应该快速坍缩为READY态。而READY态是一个稳态,该状态下的Frame代表着其的前置准备工作都已经执行完毕,这是BPM外部唯一可以使用的Frame的所处状态。
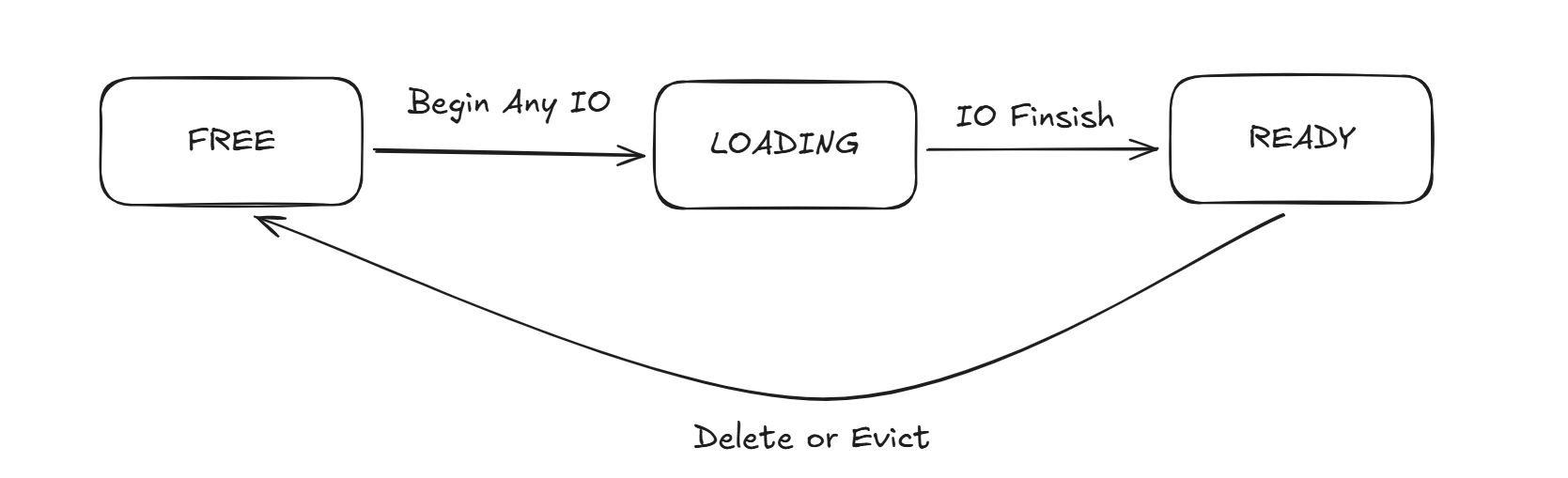
为什么要有这个状态建模?因为我想要有一个仲裁的机构,我不想后续的设计过于发散,我期望先建立出一个我认为的标准,后续的操作都往这个标准来靠。只要观测者都能够按照一定的要求来观察和使用这套标准,那我就应该能够保证一种不变式,而这些被观测的状态以及线程等本身的操作,则共同构成了一个逻辑上的协议。
前文中我们其实已经设计了一些简单的不变式:
- 所有位于free_frames_中的帧都应该处于FREE状态
- 所有暴露给BPM外部使用的帧都应该是READY状态
但是这些保证是远远不够的,我们需要逐渐来扩充我们的不变式。我们根据现有的实现来逐渐进行分析。对于一个GetFrame来说,其要处理的场景只有三种,前文已经说明过了,这里不再赘诉。我们将逐个来进行分析。
当前目标页不位于BPM中且当前BPM中有空闲槽位
在这种情况下,只需要从槽位中获取一个槽位并进行后续的初始化即可。在以前全局锁的场景中,在获取到一个空闲槽位后,我们直接就在锁内进行读盘的初始化以及后续的元信息的处理了。后续进入临界区中的执行流将不会观察到一个被弹出free_frames_并且内容并未初始化的帧。在进入后续之前,我们先来分析一下,在获取了一个可用的帧之后,我们所应该处理的操作有哪些。在有锁的情况下,这是所需要做的只是更新对应的
page_table_(BPM中维护page_id映射结构)中的信息,记录本次操作的访问记录,设置该Frame的不可驱逐状态即可,而不必要去担心IO以及状态更新之间的顺序,因为在外部看来,这些操作都是原子的。但是这一切在外面想要将IO移出临界区之后都变了。由于我们将IO拆分出去,此时我们将整个流程拆分为了多个小块,我们需要详细分析当前如何来安排这些原本原子的操作的顺序。举个小例子,在实际的IO操作完成之前,我们应该如何来进行元信息的更新,我们应该更新多少的元信息,这是之前被一个大锁锁掩盖掉的问题。如果我们在IO完成之后更新对应的
page_table_。那么由于我们在IO期间并没有进行互斥,那么其他执行流也可能进入同一个处理逻辑,此时其将无法在page_table_中看到该Frame,而其观测到的BPM状态将会是一奇怪的状态:当前free_frames_中的数量+page_table_中已使用的Frame数量小于了整个BPM的容量。我们需要考虑这种状态是否可以接受。这个问题的答案其实很明确,这是不可接受的。因为BPM的容量固定为构造时的设置这应该是一个基础的不变量,或者说,这种程度的不变量相对来说比较合理,如果要维持那种可能波动的状态。其可能存在一些奇怪的现状,就比如在极端情况下观察到当前BPM中没有Frame,这实际上是不可能被接受的。所以我们需要进行一种补偿。当然,这里其实并不是说这种波动就一定不会,你当然可以将其设计为一种正常的BPM状态,只要你本身BPM的FSM建模足够到位即可。不过我想,这种设计是相当麻烦的,我期望的是一个最小侵入的改动,既然先前有锁下的设计不会使得BPM出现这种可见Frame数量少于实际Frame的场景,那我这里也不会去变动这个不变量。
至此,我确定了另外一个不变量,对于任一一个执行流来说,其进入BPM所观测到的当前BPM的Frame数量都应该等于构造时设定的数量,不应该出现任何的波动。在该不变式的约束下,我明确了一个在当前场景下所需要做的事情,我需要在进入IO操作之前就将本次GetFrame操作已经获取了该Frame的行为发布出去。通过这样,我们就能够保证在该场景下的调用不会破坏这个不变式。
本场景到此结束了吗?当然没有,还有一个十分需要注意的,我们将该状态发布出去了,对于其他执行流可见了。其他执行流应该怎么处理这种状态呢?对于其他执行流来说,这种帧是十分特殊的,因为其确实已经存在了,但是其的初始化实际上还没有执行完成。因为其的IO还没有完全处理完全,外部能够使用这个帧吗?实际上是不行的,否则这就类似于语言中使用一个未初始化的对象一般,是一种UB操作。我们需要另外一个不变式,来屏蔽其他执行流对于该Frame的使用。我的设计如下:除开执行IO的执行流,任何其他执行流,都不可使用一个正在初始化的Frame。恰好,我们前面有一个状态就是在描述这个状态下的Frame的,因此我们可以再浓缩一下这个不变式:除执行本Frame初始化的执行流外,其他执行流都不允许使用一个其看见的位于
LOADING态的Frame。通过该不变式,我们能够保证一个执行流不会插手任何一个正在其他执行流中进行初始化的帧。至此,我们明确了在当前场景下在离开临界区之前我们需要发布出来的信息:发布在BPM中的页面映射,记录本次访问记录,修改当前Frame的pin,将当前Frame的状态置为LOADING。通过如此,我们成功建立起了一个屏障,该屏障应该保证我们该初始化执行流的后续操作不会被其他执行流所打扰。
这里实际上还有一个有趣的点,就是为什么可以保证不会被其他执行流打扰,读者可以仔细分析一下
接下来,我们离开由
BPM构造的临界区,进入我们先前所构造的屏障。在该屏障之下,我们所需要处理的工作很简单,就是IO,对于当前场景,其所需要做的IO就只是从磁盘中读取数据而已,这一块不再赘诉。我们需要分析的是,在完成IO之后,该执行流需要做什么?对于该执行流来说,当其完成该IO之后,该Frame实际上已经初始化完毕了,而这对于Frame来说是一种新的状态,我们应该将这种状态发布出去。对应的即是先前的FSM图中由LOADING往READY状态的转移。当完成了这种转移之后,page_table_中的Frame就不再是不可用的状态了。当前目标页不位于BPM中且当前BPM中没有空闲槽位
在该种情况下,其基础的处理逻辑也很清晰,就是筛选出一个可淘汰的帧,并且进行复用即可。当然,细节上仍存在部分需要斟酌,我们来进一步详细的分析。
首先毋庸置疑,是选出一个可驱逐的帧,但是这种情况实际上有俩种可能,就是本次淘汰可能根本无法选出合适的帧。此时可能是由于所有的帧都在使用中,这是一种必定出现的场景。既然如此,我们就需要对于这个场景的语义进行明确,而基于我对于代码中的观察,其期望的在这种场景中的行为实际上会有俩种,其应该既能够支持反复重试直至获取一个可用的帧或者直接失败。为了支持这俩种场景,我们需要一种开关来作为策略决策,就比如一个
bool block_on_no_frame,根据该变量来观察到底是否需要在无法获取帧时重试。对于直接失败的场景,自然直接失败即可。接下来我们将注意力集中到需要重试的策略下,我们需要来思考如何才能够实现一种重试机制。我们首先需要分析什么时候可能导致当前根本无法获取一个驱逐帧以及什么时候才可能从无法获取帧转到一个可获取的状态。对于全部无法驱逐,这种状态其实很常见,就比如若所有的已使用的帧都被pin住了,此时自然就无法驱逐,但是这种状态是合法的;还有可能是没被pin住的Frame实际上处于一种LOADING状态不可用。但是第二种状态我们实际上不需要关心,为什么?你可以先停一会自行进行思考。对于第二种场景,就是对于LOADING状态的Frame,其必然不可能是本场景下所想要查找的Frame,否则其就不可能落入这个处理分支了。所以其实际上等效于第一种场景。当然,这里可能从第二种场景继续去衍生讨论,这里先搁置。
对于第一种场景,其中的状态转移点也十分清晰,若当前的任一一个Frame的Pin降到了0,那么此时其就势必可以驱逐,因此就可以来进行通知来重试了。而这里的重试实现也相当有意思,不过由于这一块有点涉及到实际的实现上,所以这里不再进行深入。
接下来我们来进入第二种场景的衍生分析。对于第二种场景来说,其如果是其中被pin住的frame成功UnPin了,那么实际上与第一种的处理相同,我们关注到其的后半部分,如果其对应的LOADING状态的Frame成功初始化完成进入READY呢?首先,我们来分析一下当前可能的执行流,为什么会出现这种LOADING->READY的转换,因为外部调用了一个api,而这个api实际上会获取一个PageGuard,而这个PageGuard实际上会增加对应的Pin,而在这种情况下,对应的状态就坍缩为了那种普通的被Pin住的Frame的场景。所以最后第二种场景也会坍缩为第一种场景。而你想到没有,这其实也是我们先前的不变式所给出的一种保证。因为其保证了位于LOADING状态下的Frame对外不可见,这里才能够坍缩为一种场景来进行处理。
好,至此,我们结束了对于重试策略下的该场景分析,我们能够在这里先进行一次阶段性的总结,通过重试等机制,到这里代码应该能够保证获取了一个可驱逐的Frame,并且需要我们来进行后续的元信息初始化等操作。
对于当前获取的帧,其实际上存在一些不同。先前在第一种场景中获取的帧是一个空白的帧,其上实际上不承载任何信息,而这里不同,该被驱逐的帧实际上存在着先前被使用时的元信息。我们需要谨慎把控对应的处理。我们还是先回到全局锁时的处理,在全局锁时,当前场景的处理很简单,就是先清理该被驱逐出来的帧所遗留的状态,然后再把新的状态信息和IO进行初始化。正如前一个场景所需要做的,这里也需要处理对应的元信息的发布时机。由于有前文的经验,这里的分析就稍微简单一点。对于这种场景下的发布,其的考虑也基本与前一个场景一致。就是先将当前帧的新元信息发布出去。同时将对应的帧状态置为LOADING来构造一个屏障。后续的操作也跟前文的操作一致,把IO等初始化作为就可以更新该Frame的状态了。
但是!别忘记了,这里我们处理的帧不同于前文的空白帧,其是承载了信息的,如若该帧实际上为一个脏页,此时会怎么样呢?我们势必要进行写回,而这个IO是放在锁外的。我们来考虑一个严重的并发场景,若在驱逐了这个帧之后,我们立刻存在一个执行流抢占了调度,并且该执行流还是读取的这个被驱逐的帧,而且这个帧的读取请求还发生在了先前那个驱逐操作的写回请求之前。这是一个并发下一定可能发生的场景,因为我们目前没有对于这个场景进行任何保证。那么此时所导致的后果是什么?这会导致我们读取的数据实际上是一个旧数据。这是不可接受的,我们进一步从业务上来看这么一个场景。若一个请求导致了一个Page的驱逐以及刷盘,我们此时在另外一个执行流发起了针对于这个Page的请求,这个读请求期望能够看到先前写请求的结果,但是实际上由于IO调度顺序其看到的是一个旧的结果,这是不可接受的。所以我们一定得对于这种场景进行处理(实际上,这个问题是在线上测试中暴露出来的)。为什么会出现这种情况呢?这是因为page_table_中的信息与IO操作之间不再是原子的了。俩者之间消失了一个协议保证。一个重要的不变量被打破了:一个脏页被从
page_table_移除之后,下一次读取该页一定是最新的结果。这个不变量由于IO脱离了临界区而失效了。我们需要来进行弥补。为什么会出现这种情况?如前文,这是由于
page_table_的移除与脏页刷盘之间不再具有原子性保证。而我们能够通过什么操作来进行弥补?你可以使用你的方法,而我的方法是,我采用一个额外的std::unordered_set<page_id_t> evicting_pages_;来暂存当前被驱逐出去的脏页的page_id。然后根据这段元信息来做一个屏障。在任何一次CheckPage操作中,如果其获取的page_id位于该结构内,那么就意味着当前的页被驱逐但未被刷盘,位于一个LOADING状态不可获取。只有当获取的page_id不位于该结构内时,我们才能够维护先前的不变量,才能够通过该屏障。当然,在这个屏障中,我们同时也需要来根据上层所期望的,来进行一定的重试或直接失败等设计。至此,我们结束了本场景下的分析。在本场景中,其中的大部分思路与第一种场景一致。只是由于驱逐的帧的性质不同,引入了一些额外的机制来保护重要的不变量。总体来说仍然是围绕不变量本身所展开的操作。通过不变量这个锚点来简化了很多的并发场景分析
当前页面位于BPM中
接下来进入最后一个场景。这个场景相对简单。因为从场景名我们就能够明确很多东西。首先,当前页面位于BPM中,这意味着什么?这意味着我们可以直接从BPM的
page_table_中来查看到对应的帧。当然,在此之前,不要忘记此时需要先保证通过先前第二种场景中所分析出来的evicting_pages_屏障。在通过该屏障且成功在page_table_中查找到该页面帧时。此时实际上可能存在俩种情况,停下来思考一下。此时的Frame的状态可能为LOADING或者READY态。对于LOADING态的Frame,此时需等待对应的初始化完成,此时就需要一种等待机制了。对于我来说,我通过条件变量实现这种机制。但是通过条件变量来实现会存在一些隐性的问题,仍然需要一些机制来进行补偿。这里涉及到一些并发上的分析,我当前可能已经有点越界了。所以后续不再进行说明,自行分析可能的问题吧。总之,我们通过一个通知机制,使得最后的处理能够坍缩到只可能处理以及在page_table_中存在,并且状态仍为READY的帧。这维护了先前的几个不变量。然后,由于这种场景下不必进行IO,所以我们只需要进行简单的元信息更新即可。这里不再赘诉。
综上,我们已经完成了对于本次BPM设计的核心API,CheckFrameForPage的讨论。这里有些内容可能与课程要求中相违背,如果发现,请提醒本人进行修改。
我们在这里总结一下我们所使用到的所有不变式:
- 所有位于free_frames_中的帧都应该处于FREE状态
- 所有暴露给BPM外部使用的帧都应该是READY状态
- 除执行本Frame初始化的执行流外,其他执行流都不允许使用一个其看见的位于
LOADING态的Frame - 一个脏页被从
page_table_移除之后,下一次读取该页一定是最新的结果
实际上回过头来看,所用到的不变式不多,但是正是这几个不变式,构成了我们缩小所粒度的支柱。是一次相当烦人但有趣的体验。下面给出优化后个人在榜上的Rank。
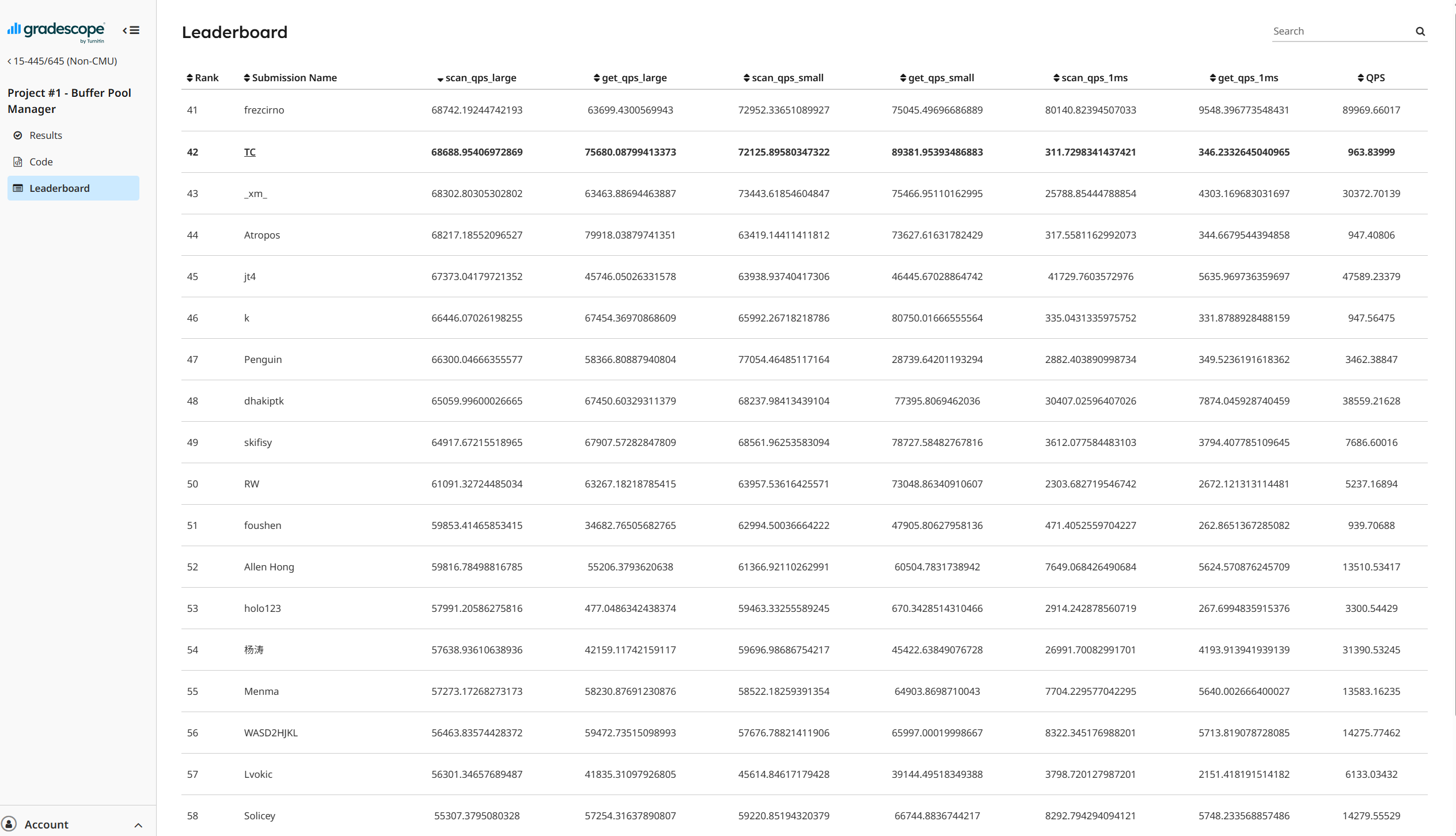
总结
总而言之,本次的优化是一个相当有趣的经历。在开始时,实际上我是一个无头苍蝇。甚至于到结束,我都有点混乱,我在一开始的尝试只是为了缩小锁的粒度而去缩小锁的粒度。进而导致了很多的无意义行为以及错误。期间AI本身也给我提了不少建议,但是给我添的乱也不少。但这一切都是因为一点,我看事情的视角错了,我不应该从锁的粒度去看待并发,正如那句话,要”透过现象看本质”。怎么才能够够做到并发,要在变中求不变,找出复杂的执行流浪潮中的锚点,基于这些锚点来逐步扩展自己稳定的领域。最后构建出一个完整的并发执行流。