TinyCoro Lab2
在本节中,我们将根据对应的TinyCoro的Lab2的内容来进行一次对应的LSM的熟悉以及各方面的一次总结还有我在本次Lab2中获取到的感悟。
协程生命周期管理
在本次Lab2中,我遇到了一个难题,”需要怎么来理解engine,context组件对于协程生命周期的管理”。该问题是主导我们如何实现后续的各个逻辑的核心。其的回答将会影响我们来如何设计engine对于协程任务的推进,如何设计context如何驱动engine推进所有的协程Task。
在开始之前,我们需要先来对于一些现有层次进行抽象以及隔离。首先,对于当前的实现来说,engine在逻辑上的地位是一把”武器”,通过它,我们能够驱动一个或多个协程任务的执行流的执行。但是,其本身并不知道如何使用其所拥有的性质,也就是其不知道如何来驱动一个协程的运行,其所能够实现的,是对于各个基本的逻辑单元,就比如协程各个状态之间的转化的桥梁的建模。我们能够通过它来驱动一些关键流程的前进。
其次,context就是上文中提到的”我们”。如果将engine类比为”武器”,那么context就是士兵。context能够利用”武器”去实现一系列的行为,在这里,所谓的行为包括但不限于驱动一个协程从提交到退出的整个行为等。所以,其相对于engine来说是一种调度者的角色,负责调度我们何时应该驱动engine执行什么行为,以及需要做什么来维护整个逻辑链条并不出错。
Engine简略
对于Engine来说,其最核心的任务为驱动协程计算任务以及IO任务。在协程中,所谓的计算任务本质上就是对于一个已准备就绪的协程进行resume,然后其会自动跑在CPU的栈帧中进行计算;而对于IO任务,协程需要提交给Engine,由Engine本身来帮忙推进IO任务并在完成之后通过协程就绪。
此时我们可以给Engine的功能下一个粗略但够用的定义,通过对于Engine的api调用,我们能够驱动提交给Engine的协程的运行。因为一个协程本质上就是由一系列计算任务和IO任务形成的,所以通过合适的调用对应的api,我们就能够推动对应的已经投递到Engine内的协程任务的执行。我们下面给出几个实际上实现的api所提供的抽象。
- submit_task Engine暴露给外部的往内部提交一个任务的接口
- exec_one_task 驱动Engine执行其协程就绪队列中下一个任务的计算任务执行
- poll_submit 驱动Engine执行IO任务,一次调用会驱动Engine进行一次内部的IO事件检测,包括提交待提交的IO,处理已完成的IO。需要注意,一次poll_submit的调用实际上可能会产出一些新的Task,这点特别需要注意。
上诉三个api即为Engine的核心api,除此之外还存在一系列的重要的api。接下来在对于Context如何与Engine交互中会逐渐提及。下面给出其中最重要的poll_submit的实现。
1 | auto engine::poll_submit() noexcept -> void |
Context核心
对于Context来说,其核心任务在于如何巧妙组合Engine中的api来驱动协程任务的完整推进,同时保证不丢失任何一个协程任务。我们本次的分析核心就在于Context这里的核心任务,在当前的设计中,我们通过Context的一个核心api来封装了整个流程,所以我们接下来的分析重点会集中在对于该api实现的思路以及对应的逻辑上。
下面给出实际的代码
1 | auto context::run(stop_token token) noexcept -> void |
该api的逻辑实际上很简洁。首先是驱动Engine处理器所持有的IO事件,然后推进协程计算任务的进行,最后判断当前Context是否已经已经满足退出条件或者休眠等其他状态,并执行不同的逻辑。看起来很简单。但是,实际上会存在很多的细节需要处理。而这些细节的核心围绕着一点,如何来正确的维护一个协程任务的声明周期。
我们首先来给出结果基础的抽象层级,对应的empty_wait_task判断当前的Context是否满足退出条件,对应的m_stop_cb为当一个Context退出时的资源清理逻辑。同时我们来说明当前期望的context退出逻辑,当对应的context投递的所有的协程任务都执行完毕之后才能够退出。所以其中退出的核心条件为如何判断当前的context中确实已经完全执行完毕对应的任务。
为了避免文字描述上的抽象,对于这种生命周期的管理,我们需要来使用一种更加形象的语言来描述,这里选择使用FSM来对于一个协程的生命周期进行描述。
协程生命周期
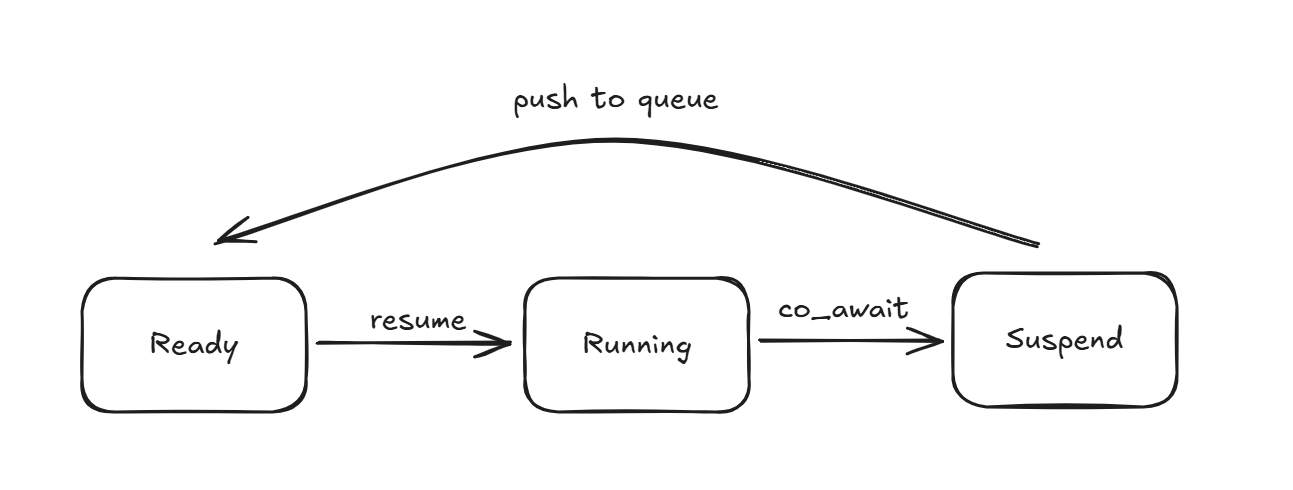
在本次的设计中,我将一个协程在程序中的流转是所位于的状态定义为了三种,分别为”Ready”,”Running”,”Suspend”。
- “Ready”代表着协程此时已经准备就绪,能够通过一次resume来跨越上一次导致阻塞的调度点。
- “Running”代表协程此时正在CPU上执行计算任务
- “Suspend”代表协程此时已经阻塞,正在等待某个条件满足,在本次的Lab代码中,这个条件一般就是某次IO操作的完成
此时,我们将整个协程的声明周期划分为了这三者,为了来验证当前的实现中是否已经能够完整的管理协程的生命周期,我们需要来分析一遍整个Engine和Context中对于整个生命周期的覆盖和管理情况。
首先我们需要来看到其中的退出条件,你需要理解为什么退出条件实际上是对应的判断协程的生命周期是否被完整的管理的关键。下面是当前context中对于退出条件的检测。
1 | auto context::empty_wait_task() noexcept -> bool |
下面给出其中几个变量在代码中的建模含义
- m_ref_cnt 当前context中处于Suspend态的协程的数量
- m_engine.ready() 当前engine中处于Ready态的协程的数量
- m_engine.empty_io() 当前engine是否残留未处理的IO事件(待提交IO以及已完成未处理IO)
接下来我们来看这几个变量如何能够来涵盖整个生命周期管理的,分析对应的代表含义以及为什么需要存在。我们将从现有的engine和context对于生命周期的覆盖入手,来建模各个变量。
Engine覆盖的生命周期
在Engine中,我们存在多个成员,包括如下几个
1 | mpmc_queue<coroutine_handle<>> m_task_queue; |
其中的各个成员在逻辑上其实就是一个协程在某个特定阶段下的代表,从观察者角度来看的话,实际上这些成员统计的是出于某个特定状态下的协程的数量。
m_task_queue成员的作用是储存当前已经就绪了的协程句柄并提供用于后续的resume操作的对象。所以其的was_size()成员属性反映的实际上就是当前处于Ready态的协程数量。m_wait_submit_io反映的是当前的Engine中等待被io_uring接受的IO事件,m_running_io反映的是当前Engine中已经完成,但是还没有被处理的IO事件。这俩者共同反映了在一个协程进入Suspend态后的内部状态转移。对于外部来说,通过这俩个状态,我们就能够观察当前位于Suspend态的协程数量。
综上,通过对于这些成员的统计,我们能够观察到位于Engine中,位于一些特定状态下的数量。包括了我们上面所提到的”Ready”态和”Suspend”态。
由此,我们根据这种状态的统计生成了俩个api,如下
1 | auto engine::empty_io() noexcept -> bool |
通过对于这俩个api的调用,我们能够观察到当前执行引擎中的部分协程,但是由于我们还还没有涵盖整个生命周期,所以还是会存在一些遗漏的协程。如果我们只根据上面这俩个api就进行对应的退出判断。势必会导致部分协程被遗漏,甚至于导致内存泄漏以及UB行为。所以我们需要在一些其他地方进行对应的补偿。在TinyCoro中,即是通过Context来对于协程的监控进行补偿。
Context覆盖的声明周期
如果你对于生命周期的管理足够敏感,你应该能够注意到,在上面Engine中,所观测到的实际上只是切实的位于对应的”Ready”态和”Suspend”态中的协程,那么,对于那些位于状态转换中的协程呢,对应的是否有能够正确的统计到,或者说,当前的是否能够成功的补偿到这一部分的统计。这是你所需要思考的内容。接下来我们进入Context是如何对于前文中遗漏的协程生命周期监控进行补偿的。
我们需要回过头来看到Context‘中的核心函数**”run”**。在这个函数中,我们可以看到一个比较有趣的实现,如果你足够敏感,你应该能够观察到这里实际上覆盖了一个状态,就是对应的”Running”态。在”run”中的第二步实际上是一种在本循环内执行所有Running态协程的行为。通过在本循环内执行该函数,我们能够提供一种保证,在对应的声明周期管理中,所有的”Running”态协程都能够被正确的执行,统计,以及转移。其中存在一个有趣的点,就是其是如何保证对应的涉及到”Running”态的转移能够不被遗漏的,你可能需要阅读engine和context的实现来理解。
好,接下来我们先来进行一次阶段性的总结,在当前的分析中,我们看到了Engine统计了位于”Ready”态和”Suspend”态的协程数量,而Context通过在核心流程上包裹对应的”Running”态协程实现了对应的位于”Running”态和处于涉及到”Running”态的俩条状态转移路线的监控。回顾一下我们前面的协程生命周期FSM图。在该图中,我们还缺乏一条关键路径没有统计,就是对应的”Suspend”态向”Ready”态的状态转移。为了完善对于协程的统计来实现安全的退出,我们势必需要完善对应这条路径上的协程数量的监控,为此,我们需要分析到底什么时候会触发这条路径以及我们如何来监控这条路径。
下面给出一个可能的并发竞态流程
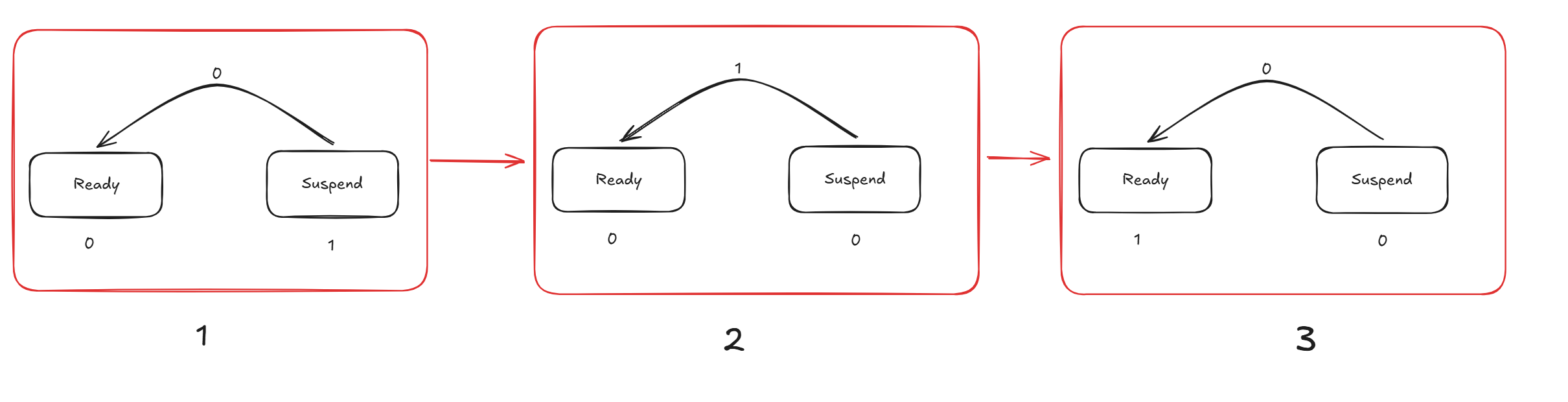
上图清晰的给出了如果我们没有对于该流程进行对应的监控时可能出现的统计的问题。在当前的设计中,一个Suspend态往对应的Ready态的转换并不是原子的,其涉及到取出sqe中的信息,解析其中的结构,调用其中的元信息并将其重新注入到就绪队列中,要是整体的监控流程监控到的**”2”**下的快照,那么其会认为当前任务已经结束,其会尝试停止对应的Context,但是实际上我们仍然存在一个正在搬运过程中的协程句柄,如果这次Context的停止导致了整体的Context的销毁,那么会导致对应的状态转移的终点将会导致一种未知的场景,也就是UB,即使幸运的,这次并没有进行对应的销毁,重新成功注入了队列中完成了状态的转移。但是这种语义是我们想要的吗?我们必须将并发以最坏的场景进行构想,所以我们必须监控这个流程中的协程数量。
为此,我们引入了一个引用计数的概念。我们尝试将这个流程中的协程使用一个引用计数留下一个钩子,只要存在这个钩子的值非0,Context就能够知道当前仍然存在一个状态转移中的协程,那么其就不会尝试进行自毁。如果我们能够更加的对于这种钩子进行精确的统计,那么我们就能够更好的使得Context感知当前的工作协程,并避免误判导致的各种UB。具体的更加详细的分析,你需要自己来进行分析以及理解。
接下来我们来分析我们应该如何来设计这种钩子。期望中的钩子自然是在对应的这条状态转移路径上的增减时进行统计,但是实际上这是很难做到的,可以自己考虑一下如何实现。在本次设计中,我们考虑扩大对应的钩子范围,我们在一个协程即将进入对应的”Suspend”态时就进行Context对于位于该路径上的协程数的++,在一个协程已经从”Suspend”态转移到“Ready”态后,就将对应的钩子数–。通过使用这种粗粒度的引用计数的统计,我们成功实现了对于该状态转移路径上的协程数量的钩子统计,并成功取得了想要的效果。而且这种对于外部的心智负担并不大,这受益于C++中的协程实现,其中的对于一个协程运行阶段的各种拆分允许我们在特定对应阶段进行一定的逻辑的注入,你可以分析一下我们实际上需要在哪里进行对应的引用计数的修改。
总结
对于本次Lab,其中最令人痛苦以及着迷的是我们到底需要如何来正确管理对应的协程的生命周期来使得能够正确的统计协程来使得Engine和Context能够真正的在任务执行完毕之后进行退出,不由于错漏而早退导致UB。而为了能够分析当前到底实现了什么功能,一个FSM建模对于生命周期这种模型来说是十分吻合的,特别就如这里,我们通过将一个协程的生命周期建模为一系列的状态以及状态间转移,再在这些状态和中间状态进行监控,我们实现了对于整体的持有协程数量的监控。这种使用建模来解析复杂模型的思路不失为一种好的方法。
实际上,在很多其他方面也能够看到FSM的身影,特别是在网络这方面。对于网络中的可靠网络传输等,由于设计到一系列复杂的实现,单纯使用文字俩描述是很麻烦且难以理解的,此时一个FSM就是”一图胜千言”。我们能够通过对于FSM的观察来分析当前的实现中涵盖了哪些重要的状态节点以及状态路径。是否存在错漏的路径,以及是否存在隐含的路径等待我们来发现以及建模等等。总而言之,当遇到一些难以分析的问题时。不妨尝试先分析出该问题的本质,然后尝试对于这个本质进行对应的状态机的建模。就比如我们上文为了解决这个Lab2的优雅退出对于整个协程生命周期的建模一样,只要我们实际上的FSM确实能够涵盖整体的流程,然后依照这个状态机进行实现,那么总归能够找到破题的思路。