MapReduce
本文进行6.824中第一个lab的分析,基于课程的要求,本文不给出对应的代码,当然,本文的主要目的是对于本个lab的实现进行自我复盘,回顾下要实现MapReduce这种框架的最小可行实现需要我们来提供什么
实现目标
填充当前lab中提供的master.go,worker.go``,rpc.go。为这三个文件填充基本的通信逻辑,要求能够内部自动进行对应的map和reduce任务之间的调度,实现外部传入对应的处理文件以及处理逻辑,由内部来自行进行调度处理,并在最后返回给调用层对应的操作完成的消息
分工
基本分工如下:
- master.go中实现框架中调度中心的职责,要求其能够管理一定的整个系统的状态信息,实现自动监管worker,实现对于worker的任务分发和状态监控,实现对于整个MapReduce执行进度的判断
- rpc.go中实现一些结构体的定义,实际上是一些通用结构体的抽离,使得对应的逻辑更加优雅,对于master和worker都可见,理论上你可以将这个文件中的内容全放到别的文件中去,但是这样相对来说不好维护
- worker.go中实现框架中实际逻辑处理者的逻辑,实际上,该文件中的地位就对标与MR框架中的MapWorker和ReduceWorker俩者
分析
我们需要详细来分析一下本lab中对应的master和worker到底需要自己实现什么功能,以及我们需要什么基本结构才能够支撑我们的自动化分布式处理任务的功能
Task
Task的结构设计是整个框架设计中的重中之重,其需要保留一个Map任务或者Reduce任务在Master和Worker之间流通的数据,需要保证对应的worker从Master中拉取任务的这个操作能够正确进行
一个Task本身存在俩种类型,我们先来考虑Map下的Task需要的信息
- 当前任务的路径。前面已说,本个lab中一个Map的Task的基本单位是一个文件,通过对应的路径,worker能够通过一个FileSystem去找到对应的输入文件
- 当前任务的状态,一个长久流通的任务势必需要存在能够标识当前任务的状态,就比如是pending,还是finished,还是failed等,这些字段是必须的,就比如,我们不会期望一个已经被完成的任务还会被重复处理
- 当前任务的类型。一个任务至少需要能够区分其是Map还是Reduce类型,当然也可以单独的抽离出俩个特殊实现,个人为了简单只是使用一个普通的字段进行标识。同时需要注意的是,为了后续能够进行退出以及其他的扩展操作,个人维护了一个字段用于标识当前任务到底需要worker执行什么操作
- 当前任务的部分额外状态。为了方便后续的扩展,比如一些容错处理等,我们可以考虑维护一些额外的元信息字段,最简单的,就比如一些时间信息,方便后续最直观的超时处理的预留拓展
Master
对于一个调度中心,我们需要维护一系列的元信息来支持我们后续的系列维护。首先从Master所需要实现的功能入手,来逐个分析需要使用哪些结构储存元信息
需要执行的任务。本次lab中对应的任务由外部传入,具体的为一系列的文件,每个文件即为一个任务。也就是说,本次lab中省去了关于一个大文件分割的要求,直接提供了对应的split方便我们使用,为了能够后续使用这些文件,我们需要储存这些文件的信息,具体的,在当前lab中,即是对应的路径名
需要分割的任务数量。在本次lab中,对应的Map的Task数量与传入的文件数量一致,即一个输入文件即可作为一个Task进行处理。对于Reduce的Task数量,其本身应可由上层的调用者进行指定,即需要信息来储存该外部指定的最终期望输出的系统中Reduce阶段的Task数量。因此,对于Map的Task数量,我们不需要储存,可以直接根据传入文件的数量进行判断,但是外部指定的最终输出文件数量我们需要储存
当前系统中的任务进度,在一个MR框架中,自然而然存在俩个阶段,一个Map工作阶段,一个Reduce工作阶段,其俩个阶段不存在交错,本次实现中需要对这俩个阶段是否完成进行标识。同时,lab中要求我们提供一个可以标识当前系统是否完成的方法,为了实现,我们可以使用这里的这俩个阶段标识来提供该方法
当前系统中的任务状态。系统中一个任务是交由一个worker处理的,即Task是绑定对应的Worker的。虽然在本次lab中,实际上即使Worker崩溃了对应的已经完成的Task结果其也不会丢失,因为只是保留到本地的磁盘中。但是在论文中,我们也了解到,为了提高分布式下的扩展,我们应该维护对应的Worker与Task的对应的信息,无论是Map还是Reduce类型的,这样方便之后在一个Worker崩溃时候的容错处理。当然,在我们本次lab中,我们不用实现如此深的容错机制
Worker
对于一个Worker,相对来说,我个人倾向于将其设想为一种无状态的模式,应该一个worker无状态才不会牵连过多的崩溃时行为,但是其本身至少需要做几件事,应该在MR框架中,对应的**Worker**任务处理完成之后是会将文件写入一个**FS**的,所以我们至少需要维护对应的Worker与对应的Task之间的部分信息,当然,这个可以直接放置在Master中去管理(个人是如此做的)。但是其本身也会引申出来一个问题,就是Master也需要了解当前的Worker到底是一个怎么样的Worker,才能够进行对应的映射建立,所以一个Worker本身需要拥有一个属于自己的元信息,但最好足够简洁
- 唯一标识符。个人设计中,利用一个简单的UID来进行对应的worker的标识,但是由于Master启动时是不了解对应的下属的worker信息的,所以为了方便,我们考虑该信息由Master进行统一分配,具体的想法就是每次worker启动时去申请Master对应的注册信息,然后由Master本身来管理这个信息
- 当前任务元信息,无论如何,一个worker想要实现其的功能,那么其必须保留一定的任务信息,即每次拉取之后的任务信息。然后其才能够在其内部进行处理,当然,理论上你可以不保存这个任务元信息,只限制对应的内部调用的信息流转,但是你应该也能考虑到这种设计上的麻烦
状态
为了能够更好的理解这个lab,我个人简单的将对应的Master和Worker的流程分割为了几个状态
其中Master的状态很简单,就只有以下几个。
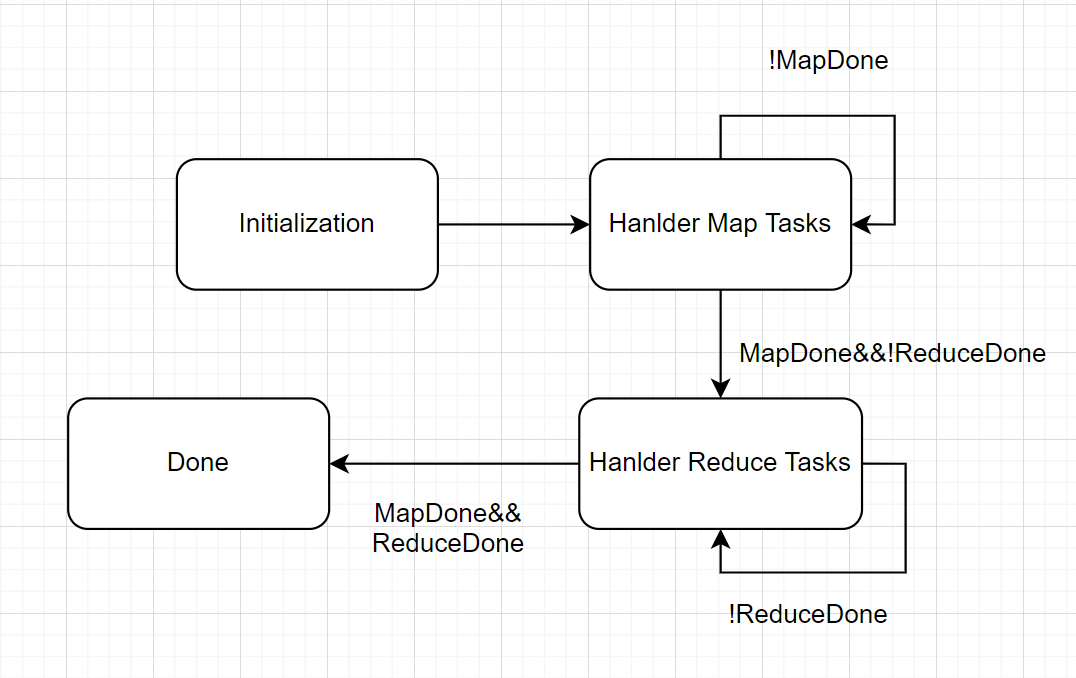
我个人的考虑是,对应的Master在初始化之后,其就进入Map Task的处理阶段,在该阶段,其会不断检查一个MapDone标志是否被置为true来判断是否需要进入下一阶段,对应的Reduce Task阶段同理。在俩个阶段都走完之后,其会进入结束阶段,在该阶段中其会上报对应的状态,告诉上传已经完成任务。
事实上,在我个人的设计中,对应的Hanlder Map Tasks阶段的判断是Handle Reduce Tasks阶段判断前每次都会进行的,这里的状态图没有列出对应的状态回退时的状态转移。
至于Worker的状态,其也很简单
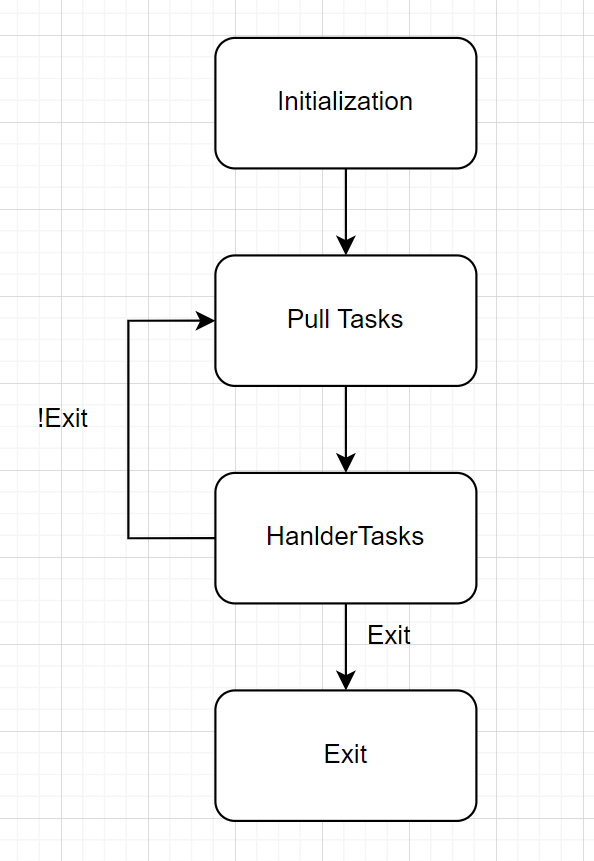
具体流程就是在Initialization阶段之后,开始循环的拉取任务,如果任务类型不为Exit,那么其会一直拉取,否则其会直接结束进程。整体的状态转移图并不复杂,主要在于其中的一些状态本身的实现。
无论对于Master或者Worker,其首先需要考虑的都是对应的Initialization阶段需要初始化什么数据。由于本个框架实际的启动逻辑是这样的,其先启动一个Master实例,然后再逐步启动多个Worker实例,所以我们对应的俩个的初始化之间的数据成员需要有一定的先后顺序以及对应的职责需要清晰。
下面分析一下个人实现的程序中的几个流程
- 在Master的初始化中,我们需要去读取应用层传递过来的任务以及对应的设定的参数(ReduceTasks的数量),并且根据这些外部的信息以及内部自己预设的信息初始化我们对应的结构体,在本次lab中,即使一个master结构体
- 在Master初始化之后,其对应的不需要主动操作,其本质上是一个服务器中的服务,等待他人调用即可
- 对应Worker初始化,其需要在启动时候去Master中注册本身,为此,需要保证Worker启动在Master启动之后,这个由lab本身保证了。因此,在Worker启动时,我们可以放心去调用对应的RPC方法。
- Worker启动后,其主动发出一个请求到Master中,像其中请求注册,若成功,Master返回一些信息。Worker持久化到本地作为唯一标识,在之后,其开始不断向服务器发起拉取任务的请求(通过RPC),直到收到一个类型为Exit的请求后,Worker退出
遵守课程的要求,本文不给出任何对应的实现代码,主要是理清对应的实现思路以及基础的实现逻辑,目前已经基本理清了本人在实现本lab中的一些逻辑。
⚠️ 警告:本文为本人完成 6.824 作业后的复盘笔记,未包含任何作业代码,也不建议作为作业实现参考。请严格遵守课程 Honor Code 独立完成。