AsyncLogger
本节进行一个异步日志打印组件的实现分析
实现动机
本组件是为了避免在一个项目中需要的日志库中,因为使用简单的同步日志打印导致对应的阻塞关键的逻辑操作,即避免由于对于整体项目的日志检测导致的项目整体的性能下降,自然而然想到使用多线程,异步来实现一个异步日志组件来实现对应的日志的记录,避免对应的IO操作的阻塞。
总体需要以下这么几个子功能:
支持不同的日志级别,日志级别的区分是一个日志组件中所必须的,其能够在后续的使用中区分当前的error级别,以及后续对于日志文件的维护筛选起到很强大的作用
支持日志的模式化输出,一个项目中的所有的日志都应该支持一个统一的格式,这样能够方便后续的审计等操作,而且这种统一的格式能够避免不规范的麻烦
日志最终输出的日志文件名称应该能够一定程度上被自定义,这样在后续对于各个模块的日志区分时可以通过一些工具快速的进行筛选。
日志本身是IO操作,为了避免频繁触发IO导致的用户态与内核态的切换开销,势必需要引入一层缓冲来进行日志数据的缓存,本实现中考虑使用双缓冲或者说多缓冲机制来进行这种日志的缓存。
子组件实现
类型
1 | enum class LogLevel { |
在日志组件的实现中,一般会使用枚举来实现日志级别的区分,枚举本身能够天然的根据声明的顺序来进行对应的级别筛选。如:声明顺序越往后的对应的级别就越高,对应的整数枚举值就越高,可以方便后续的对应的日志级别的控制。
缓冲区
1 | class FixedBuffer { |
一个缓冲区的实现在一个高效的日志组件中是必不可少的,如果一个外部的日志调用就出发一次实际的磁盘写入,那么将会导致对应的IO零碎化,也就是天生的破坏了对应的IO串行。
通过使用缓冲区来进行对应的日志的接受,我们能够解耦对应的日志的生成以及实际的日志写入操作。这种解耦能够天然的进行一次填谷的操作,避免由于零碎的日志请求多次触发导致多次陷入内核态与用户态的切换。同时,也能够进行对应的削峰的操作,使得突发的一系列日志请求不会突然压垮内部的线程,实际上是通过将多个零碎的短IO请求合并为一个大的缓冲区的IO写入请求。
除此之外,这个日志缓冲区还存在一个非常重要的作用,实际上也是一个最本质的作用,就是其能够保证对应的并发下的日志有序,避免由于并发的操作导致对应多个日志产生的IO流互相交错导致最后产生的日志文件乱码。
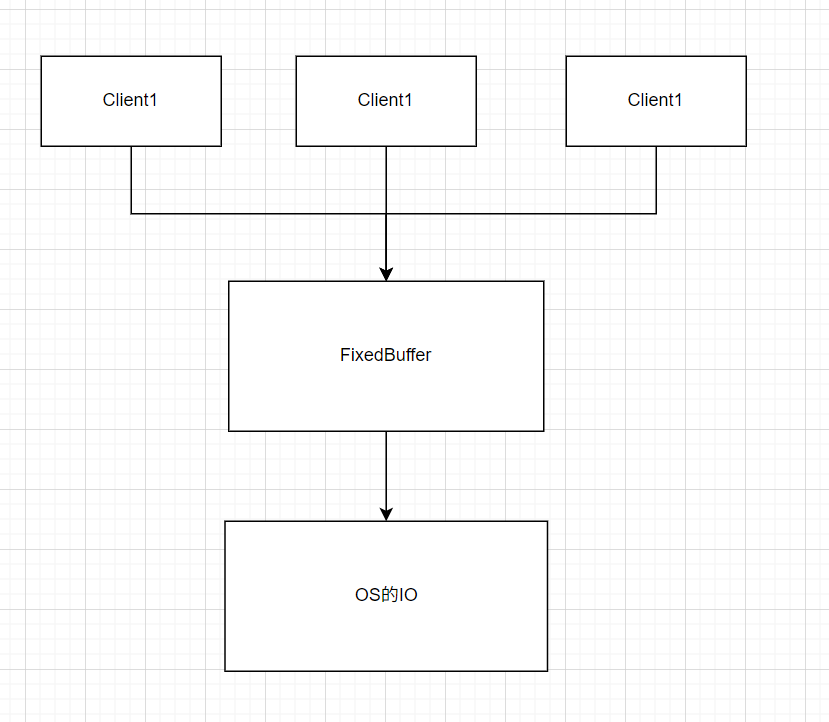
对于一个日志缓冲区,同一时间可能存在多个生成者请求储存对应的日志,此时对应的请求是并行的,如果不对于对应的日志进入缓冲区的顺序进行对应的约束,就会导致最终出现在缓冲区的数据可能是一个乱序的结果,具体可以参考标准C++的cin/cout流与传统printf和scanf之间的冲突。
实现
一个日志的缓冲区需要具有几个重要的性质
- 整个缓冲区的大小
- 当前缓冲区剩余空间的大小
- 当前缓冲区已有数据的大小
- 当前缓冲区中对外的允许数据流入的接口
- 当前缓冲区中数据可被使用的接口
- 当前缓冲区可以复用的接口
总结出来其实只有最本质的俩点:
当前缓冲区是否还可接受数据,当前缓冲区是否可以使用。
在本次的实现中,我们使用char定容数组来进行数据的承接,使用cur_指针来指明当前缓冲区内下一个可写字节的地址。通过指针操作来加速各种的已有数据量,剩余容量等的计算。其中大多都是平平无奇的实现,需要结合实际后续对于该缓冲区的使用来进行分析。
文件IO
文件IO类的实现是日志类的核心,其涉及到的是最本质的文件IO的实现,在本次的实现中,考虑该LogFile类只提供最简单的文件IO的接口的封装,不考虑复杂的内部逻辑,提供简洁的API接口让上层去进行排列组合,其实也是一种端到端的思想,如果想要在这个文件IO内部去实现复杂的多线程写入等的逻辑,可能能够在部分场景中带来一些优化,但是实际上却不够通用,所以本次考虑实现的是一个简洁的LogFile类而不是一个完善的LogFile类。
1 | class LogFile { |
在本次的设计中,考虑一个LogFile类需求如下
- 根据一个简单的用户传来的前缀名能够生成一段唯一标识的名来作为本次日志记录的储存文件名
- 允许用户能够自定义一次日志文件的最大大小,所有通过该工具类生成的对应的文件不会超过这个大小
- 当本次日志文件写入会导致对应的文件大小超过最大文件的限制时,需要能够自动进行分文件的写,同时,需要保证对应的文件标识名与本个实例类一致方便维护
实现
需求分析:
- 自动生成唯一文件名。允许用户自定义一个前缀,类内使用当前调用的时间撮进行拼接,最终的文件后缀名为**’.log’**,最终的格式为
prefix.yyyymmdd-hhmmss.log,其中prefix为用户指定的前缀,yyyymmdd-hhmmss为当前格式化的时间字符串 - 我们希望我们当前的文件IO类具有一定的扩展性,即:其能够允许外部实现自己的文件缓冲区,而不是强绑定先前实现的FixedBuffer类
- 自动处理文件过大时的分文件写入操作
- 该文件工具类应该能够直接最直接的数据强制刷盘,保证外部在崩溃时能够完全的写入一次的日志文件数据。
关于上面3点,我们来逐步解决
对于第一点的自动生成文件名,其是最容易解决的,由于在本个文件类中我们可能会出现日志文件的分片,所以我们需要持久化对应的前缀名,接下来我们通过调用对应的系统api来获取当前的系统时间,接着对这系列字符串进行拼接(附带.log)得出一个完整的日志文件名即可使用。
对于第二点,这个稍微涉及到了接口设计上的规范,一般来说,一个类想要实现一个更加通用的接口,其需要使用的思想不再是面向对象,而是面向过程。如果说,我们使用面向对象的设计,那么该类中会储存一个对应的参数成员,这能够使得更加的内聚,但是一定程度上也限制了对应的扩展性,就比如下面我们设计的数据接口
1 | void append(const char* data, std::size_t len); |
我们的参数类型是const char*,也就意味着所有的基础字符串都可以被该类处理,这也就意味着只要外部传递进来的是一个char* 数组,内部即可处理,不再需要像面向对象中对象类型的强绑定导致的一些约束。就比如,我们前面实现的FixedBuffer类,其本身不可以作为参数,但是由于其底层数据储存使用的是char*数组,所以可以直接使用内部的数据进行对应的日志打印。
这种操作给我带来了一种启发,就是我们想要一个类实现更好的对外的兼容性,我们对应的对外api设计就不能过于OOP化,而是应该更加的面向过程,更加的贴近基础的数据结构/数据类型。这样使得在保留原有的功能的同时,外部的封装也是被允许的,而且不会影响到内部的使用,你可以在外部对于数据缓冲区进行各种封装来自定义功能,只要你保证你存在一个最基本的数据接口即可。这正是面向对象和面向过程进行交织所能带来的优雅性。
当然,当前的设计虽然提供了一定的可拓展性,但是同时带来了一些心智负担。即,你无法使用现有的常用的数据类型,即string等。但是这个不是问题,你大可通过一个适配器函数来进行对应的调用,一般来说,这种适配器函数需要放置在对应的调用该LogFile类的主类中,通过一层接口来平衡OOP和POP之间的关系,在接口抽象性与复用性之间找到一种权衡。
至于第三点,我们在类内维护了多个全局的变量,其一是当前打开的文件已经写入的字节数,其二是外部规定的本次写入所最大的容量。在每次进行append写入时,我们判断当前已经写入的字节数再加上本次要写入的字节数是否大于规定的最大字节数,如果是,我们将会根据当前的时间撮以及先前传进来的前缀来生成一个新的日志文件进行储存。
最后,该类文件IO类都应该支持一个强制刷盘的操作,保证外部在崩溃时能够强制把剩余的缓存而未被写入的数据持久化,避免丢失重要数据。具体即是通过显式调用flush来实现的。
至此,我们结束了在外面的日志类中俩个关键的子组件的实现,其中FixedBuffer主要是对于日志数据的缓存,起到一个削峰填谷,保证有序的作用。而LogFile是为了实现一个基本的文件IO持久化的工具,提供基本的分文件以及落盘的操作。下一步,我们就应该来进行我们上层的组合,来实现我们真正的异步日志工具类了。
异步日志类AsyncLogger
对于本次实现的日志类,我们的基本实现要求是:日志在系统中的全局可用性。在这种驱动下,对应的我们自然而然将该异步日志类实现为一个单例,实际上,可能存在多个模块之间需要单独记录自己的日志的需求等等,不过这不属于本次demo的讨论范围,感兴趣的可以自行实现。
为了实现一个全局共享的属性,我们自然考虑使用单例实现日志类,这是基础的内容,我们不再赘诉,主要来分析一下我们该日志类需要具备什么功能。
- 日志类需要通过组合缓冲和文件IO来提供具体的功能,如,通过缓存来承接对应的日志数据,通过文件IO来实现日志的落盘
- 日志类需要实现异步的操作,避免发出的一个日志请求会阻塞住日志发起的线程,这是本类所需要实现的核心,否则一个同步的日志类不需要我们耗费这么多心神
- 该日志类应该在一定程度上具有高效性,毕竟对应的日志落盘线程跑满CPU导致其他一些工作线程的挤占
- 一个日志类不一定需要提供一个外部设置格式化的接口,我们考虑内部约束对应的日志格式来避免允许动态设定日志格式的麻烦
我们主要注重于本次实现中对于异步的实现和一些个人的优化思路。
要想实现日志操作的异步,自然而然的想法就是避免在调用对应的接口时出现直接的写入操作,而是将该类写入操作分配给后台线程进行处理。
我的思路如下,每次外部的日志调用,我们在本次调用中将对应的数据格式化后拷贝到该日志类所提供的缓冲区中,然后直接进行返回。在这种外部的不断操作下缓冲区不断被填充知道后续唤醒后台的工作线程来进行一次总的缓冲区内部的数据的IO写入。
在这个思路中可以看到,外部的调用会存在一个开销,就是对应的数据格式化以及拷贝的开销,这个后续可以考虑进行分离出一个额外的格式化线程以及格式化缓冲区进行外部线程的压力分担,这里为了简便没有进行实现,不过由于都是内存上的操作所以事实上这个在目前来说理应不会是瓶颈,所以还没有进行实现,感兴趣的可以自行测量性能进行对应的优化。
下面先给出一个实际调用中对应的日志输出在文件中的显示格式
1 | [2025-07-06 16:01:19.409][23100][INFO][E:\distributedServers\AsyncLogger\PerformanceTester.h:40]Thread 0 Log 0 Msg XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX |
其中分为几块内容
- 头部 包含 [ 时间 ][线程ID][日志级别][调用文件路径:代码所在行数]
- 内容 包含 用户传入的消息体参数,使用’ ‘进行分割
下面为一次日志输出调用时实际调用的函数,注意到其中存在一个formatToBuffer函数,其实际的约束了对应的头部和对应的内容体的消息解析。对应的即使对于本次log调用的可变参数列表的解析
1 | template<typename... Args> |
下面来分析对应的格式化操作
1 | template<typename... Args> |
在本次顶层调用中,对应的参数的职责分类其实很明显,前三个参数都是交由头部来进行解析,用于基本的日志格式约束,实际上,我们的设计中这前三个参数都是由系统内部来自动进行填充,不会交由用户来自行进行传递的。
接着是对于可变参数列表的解析,本次设计中利用了C++17中对于可变参数列表的折叠表达式的支持,避免了复杂的解析,同时我们还约束了事实上每一条日志在缓冲区内的位置,即,每条日志独立的占据文件的一行,这是一个很好的规范。
接下来考虑对应的头部和可变参数列表的格式化操作,先来看头部的解析操作
1 | void formatHeader(LogLevel level, const char* file, int line) { |
对于整个头部的解析,我们可以简单的总结为三板斧:格式化出对应的实际日志中需要的字符串,计算该字符串所需要的长度,填充中预留的缓冲区中并继续拷贝到实际的日志buffer中。该头部格式化和对应的单个参数格式化都是该三板斧,没什么好讲的,下面给出单个参数的解析。
1 | template<typename T> |
现在,我们了解了实际的一次日志格式化的流程,回到对应的外部的log调用,我们来分析一下此处的逻辑实现。在本次日志打印接口的实现中,我们考虑实现一种双缓冲(多缓冲)的思路来优化对应的缓冲实现,简述如下:
在AsyncLogger的主线程中,我们同一时间着俩个缓冲区,其中一个是current_buffer_,另外一个是next_buffer_。对于这俩个buffer,本质上都是相同的,但是其的工作地位不同,为了起到双缓冲的作用,我们会在每次log调用时去判断current_buffer_中的剩余控件是否比设定中最大的日志长度(本次设计中为4kb)还要小,如果剩余空间小于当前这个长度,那么我们就认定为当前的buffer已满,其应该也能够被后台的线程去工作持久化到磁盘中去。所以我们在本次的log中就进行对应的log所使用的buffer的切换。在这个过程中,我们实现了俩个重要动作:1.实现了当前承接数据的缓冲区的切换,将对应的已满的缓冲区推入到后台线程的工作队列中去;2.通知后台线程开始工作,这个动作会使得工作完成后刷新现有的缓冲区,并在一定程度上能够实现内存复用(后续分析)
具体的即是通过下面这段代码实现的
1 | if (current_buffer_->avail() < kMaxLogItemSize) { |
工作线程
接下来进入到本个日志类的重中之重,后台工作线程。
预先分析一下该线程存在的动机,该线程的动机
- 消费前台生成出来的大块日志缓冲区
- 修改对应的缓冲区状态,实现内存复用
下面给出对应的实现
1 | void threadFunc() { |
在该后台线程的初始化过程中,我们省略几个无关紧要的内容,主要在于内部的逻辑处理以及怎么实现内存的复用提高性能。
在该线程函数栈中,我们初始化了多个基础组件,文件IO组件,缓冲区组件等。在实际的进入对应的while循环体处理逻辑逻辑后,我们首先对于现有的任务队列buffers_to_write的状态进行查询,如果为空,则进入条件变量开始等待被唤醒。否则,我们将把当前快照下的所有的日志数据都压入任务队列中,具体的则是以下实现
1 | if (current_buffer_->length() > 0) { |
通过这样,我们获取了当前系统中所有等待打印的数据,在当前所有的日志任务都存在对应的队列之后,我们使用栈内对象将其移动出来,然后函数将离开锁的临界区。此时接下来我们会将该日志类中用于接受数据的current_buffer_赋予其一个全新的缓冲区,此时可能是新建的缓冲区,也可能是后续被复用的缓冲区。但是无论如何,我们保证该缓冲区一定有效。
再接下来,函数的逻辑离开了对应的临界区,此时对应的任务队列为空,锁被释放,缓冲区为全新的状态,外部的日志写可以与后台进行并发进行。
在后台函数体内,在交换了对应的任务队列之后,其开始进行处理,具体的则是遍历当前队列中的每一个任务。若其的长度非0(即内容有效),那么就通过对应的文件流进行对应的日志的写入,由于对应的整个IO操作位于一个循环体内,所以相对来说可以利用对应的IO串行的性能。
在完成了任务队列中的所有的任务之后,我们开始对于整个后台线程的函数栈进行一次重置。具体的,就是如果存在先前俩个预创建的buffer为空,则从对应的该线程函数栈中的临时工作队列弹出任务节点,并清空后赋值给对应的原先的俩个成员实现一种初始化,此时可能存在多余的任务节点,可能是由于先前的某个时刻的并发压力导致的创建的多任务节点,我们这里的设计是简单的丢弃,后续可以考虑进一步的复用,但是个人感觉在此栈上留存俩个buffer已经足够,留存过多会导致栈帧过于庞大。
最后就是在线程退出时的行为,需要了解的是,我们的文件IO使用的是ofstream流,实际上也可能存在数据的缓存,为了避免一些重要数据的丢失,我们应该在线程退出时确保所有的数据都已经落盘,避免一些数据丢失带来的麻烦。
总结,在本次后台工作IO线程中,我们实现了一定程度上的缓冲区的内存复用,虽然实际上可能会存在生成者与消费者之间速率失衡导致的缓冲区被频繁创建导致的栈帧的不断庞大,这是之后需要优化的一个方向。
性能
对于本异步日志类,个人进行了一个基础的性能测试,主要是在不同线程下对应的日志落盘的效率时间,意料之外情理之中的是,目前这个异步日志工具类在多线程的环境下对应的性能劣化严重,如下
| Threads | LogsPerThread | TotalLogs | Time(s) | Throughput(logs/s) |
|---|---|---|---|---|
| 1 | 10000 | 10000 | 0.0473013 | 211411 |
| 2 | 10000 | 20000 | 0.103107 | 193974 |
| 4 | 10000 | 40000 | 0.303058 | 131988 |
| 8 | 10000 | 80000 | 0.743923 | 107538 |
当前的设计在当线程写入的情况下表现良好,能够达到将近21klogs/s的量级,这个性能相对来说也是够用的了,不过在多线程并发下,对应的TotalLogs上来后,对应的吞吐量下降,我个人的猜测是因为在现有的设计中,由于只存在一个后台线程,对应的处理效率上不来,而且在并发量高的情况下会花费更多的事件在缓冲区的创建下,这也是由于后台的工作线程速率上不来导致数据堆积。所以后续应该考虑在多线程的情况下优化线程模型,使用线程池来进行对应的日志数据的收集,而不是现在的统一小buffer管道导致对应的瓶颈。
所以,接下来的进一步的优化方向是:
- 优化多线程模型下的日志数据收集方式,使用别的方式来替代现有的统一的流入小FixedBuffer中,将FixedBuffer大小扩大并不是解决之策,我们需要使用别的方式,就比如线程池,或者说缓存池来缓解当前多线程的数据接受瓶颈
- 优化异步日志类的消费者线程,当前的消费者线程只存在一个,对应的IO操作都由一条fstream管道来进行流入,这在一定程度上限制了对应的处理速率,但是这是现有的日志模型的限制,即一个日志类同一时间只能写入一个文件。如果存在别的应用场景,可以考虑优化这里的单消费者模型,可能扩展到多消费者?
经验
锁的使用并不是一个设计的性能瓶颈,锁的竞争才是瓶颈,在本次的设计中,对应的后台线程与对应的前台的log调用会涉及同一个锁的竞争来保护当前buffer的使用,这个会导致双方的各自多个方面围绕这个锁相互影响,我们对应的优化操作应该集中于这种临界区的优化。就比如,这里一次的后台线程调用会将当前类中所有的任务一次性的取出,减少遍历以及单独的取出操作的开销等等。