ResServer
本节进行资源服务器的简单分析
基础逻辑
为了提高一个我们资源服务器的吞吐量,自然而然的,我们需要考虑使用多线程来进行对应的资源服务器的搭建,因为IO操作是耗时的,资源服务器需要将对应的资源持久化到服务器上,那么势必会带有对应的IO操作。如果只是一个单线程的服务器,势必会导致被阻塞,这种吞吐量是很低的。
我们考虑一种情况,就是IO操作本身对于OS来说是同步阻塞的,这是由IO操作本身的性质来说的。但是,这并不意味着我们的业务层的感知就一定会是同步阻塞的,我们完全可以通过引入一层间接性来进行这种同步阻塞等待操作往异步操作层面的转换。再次强调一遍,我们这里的操作本质上也还是一个同步阻塞操作,这是一个IO操作的基本性质,我们所能做的不是去修改这个操作的本质,而是在这上面去封装它使得用户层对于调用的感知是一种异步的操作。
具体可以去学习Linux下的5种IO模型,其中有一个特别需要明确的点,不同IO模型之间是正交的,不是互斥的。
实现动机
前面已经多次提到,IO操作本身阻塞的性质无法改变,那么,我们只要在一个线程中发起了一个IO操作请求,那么势必会阻塞当前线程,我们想要实现一种在用户层面异步的感知,我们的关注点就不能关注于这种发起IO操作的线程,而是应该拔高我们的视角。就比如,看到调度这些实际发起IO请求的管理者线程。
下面给出将一个IO操作转变为一个异步操作的感知情况。当一个客户端连接请求到来时,我们习惯性的从一个iocontext服务池中去取出一个服务来管理该次连接。在本次会话管理中,假设对应的客户端发起了一次数据包上传请求(可能是要通过聊天来传递多媒体信息,上传自己的头像资源……),管理着该连接的iocontext服务会接受到这个请求(注意,这种请求是涉及到大量的磁盘IO工作的),如果直接由iocontext服务本身来处理这种IO操作,那么势必会阻塞这个服务本身。那么,在处理当前IO操作的过程中,如果存在新的数据包处理请求到来,或者说,顶层又给当前的iocontext服务分配了一个连接处理的要求,都会因为当前被阻塞了而无法执行,必须等到对应的IO操作实际结束之后才能够处理这些请求,这在拥堵情况下势必会造成很大的时延,这是不可接受的。
为了解决一个IO操作阻塞住整个服务的情况,我们自然而然的选择引入一层间接性(间接性在设计中也是一个常客了)。既然在本线程中处理IO请求会导致对应的阻塞,而且这种阻塞不可避免,那么我们就考虑就对应的IO操作给分离出去,让其在别的线程中去进行对应的处理。即一种很平常的思想。在陈硕的《Linux多线程服务端编程》一书中有提到这种的相似场景,书中的问题是**多线程程序如何让IO和’计算’相互重叠,降低latency(延迟)**。其中详细的解答了这个问题,值得一读。
对于我们这里的场景,我们需要明确一下我们讨论的对象,我们讨论的是一个资源服务器处理一系列IO请求时候的性能问题,实际上,我们在这里存在容易误解的一点,就是在我们实际的聊天服务中,这种多线程其实不一定能够提高对应的一个IO服务的响应时间,考虑一个实际的使用场景,一个客户端在发送对应的文件上传请求后,其需要等待对应的文件处理完成之后的服务器响应,(提前说明,在我们的多线程服务器中,对于一个IO操作,为了简单,我们还是串行的进行的),对应的响应时间其实是跟对应的单线程服务器中没有什么区别。吗?
上面的场景其实是相对于一种特殊情况的,就是并发请求量不高的情况,如果说对应的服务器的并发量是与单线程时候的并发量差不多的情况下,其的提升其实相当有限,或者说甚至是劣化的,其的应用场景实在并发请求数上来之后的处理效率问题。单线程本身其实有一个与生俱来的特性,就是其天生的会限制对应的CPU使用率。在现代化的多核机器中,就比如一个8核机器中,你如果开辟一个单线程服务器,那么无论你如何优化,这个服务器最多只能应用到对应的1/8的CPU资源。这里你其实会想,这里的CPU资源的利用率好像跟我们的磁盘IO的使用没关系啊。但是事实真是这样吗?
我们强调过,磁盘IO其实本质上是阻塞的,对于一个线程,其一个快照只可能最多存在一个IO请求在运行,这是由磁盘IO的阻塞本质决定的。也就是说,无论你如何优化你的单线程服务器,其每一时刻都只可能发出一个IO请求。那么,我们来考虑使用多线程的情况。对于多线程的情况,即使其每个线程同一时候都只能发出一个IO请求然后被阻塞,但是多个线程那也就意味着会发出多个IO请求。就比如你在一个8核机器上开辟了8个线程,这每个线程都发起了一个IO请求然后阻塞,此时相对于单线程来说也是一个巨大的提高,这也就是多线程给出的优势:其不是优化一个IO请求的响应时间,而是优化在高并发下的平均IO响应时间。
同时,需要注意这里存在一个边界效应,这个熟悉多线程的应该很了解。就是我们机器的IO资源是有限的,即使你开辟了很多的线程同时发出对应的IO请求,但是对应的总线就那么大,在你逼近对应的边界值时再开辟线程就不仅不会提高平均响应时间,相反,其会开始劣化了,因为存在对应的线程切换的开销,这个需要在各个机器的实际使用环境中去进行测量,需要用数据说话,这里不再赘诉。
总结,我们使用多线程来实现一个资源服务器的动机,是为了提高对应的高并发下各个用户的平均响应时间,其本身还是受限于本地机器的性能,对应的耗时IO等瓶颈。但是相对来说,其在现代的多核机器上能够更好的压榨对应的性能。
实现思路
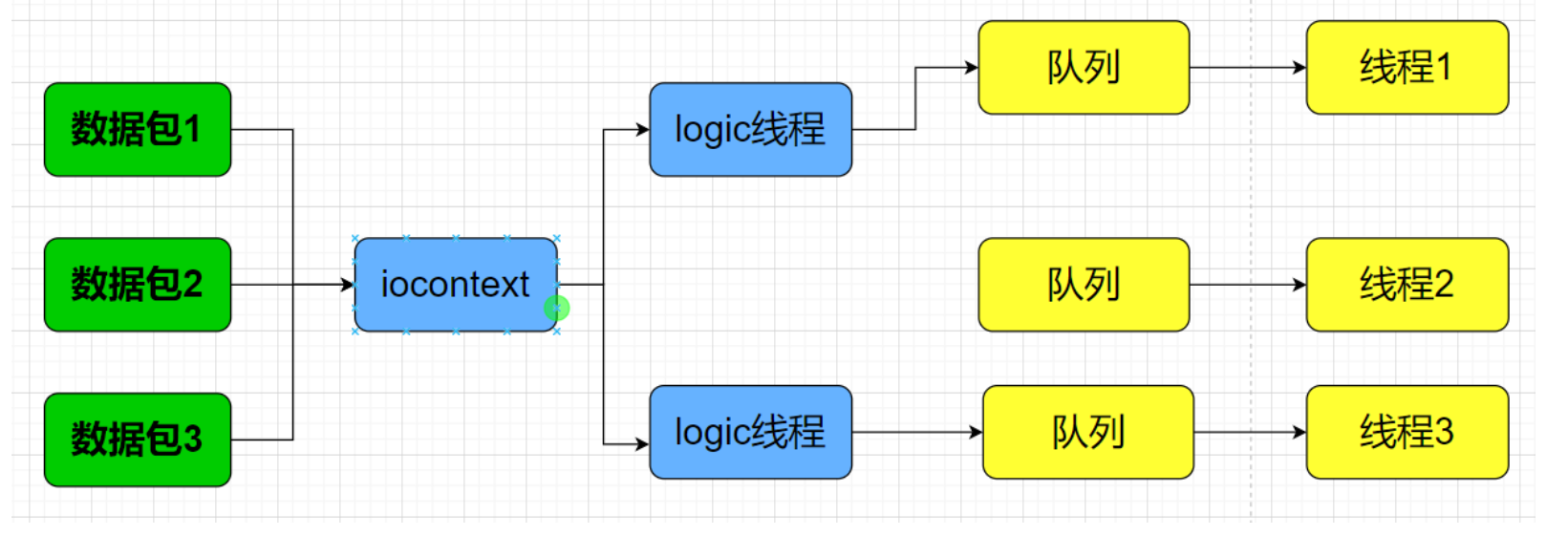
多线程的第一版逻辑如上图,其对于每个IOcontext,其都是共享一个IO处理的线程池。对于该IO线程池中的每个线程,其都存在着一个暴露给上层的队列,该队列允许外部进行任务的推送,避免因为线程本身的挂起而导致对应的任务丢失。在实际的设计中,这种结构会被封装为一个类,其中的成员变量存在一个消息队列和后台处理线程,之所以是后台处理线程,就是为了避免因为消息队列位于该IO线程上而导致无法接受对应的信息。
下面进行一次流程的推演,当用户连接上服务器后,其会被分配一个iocontext进行管理,在本次连接会话中,其可能发出一个传输大文件的请求,就比如4M大小的包,这种大小的包对于TCP来说肯定是会被切包的,最终服务器方的感知就是多个顺序数据包的状态。那么,就需要来对于这些顺序包进行对应的处理,对应的iocontext在收到这些数据的时候,不会对于这些包进行处理,而是进行一层包装,对应的,这里是将一次请求的一个特定属性进行哈希值处理,将其丢到对应的处理文件IO的线程池中去,通过哈希值来取出对应的IO处理线程。接着逐渐将这些顺序包丢到对应的线程的队列中,之后对应的后台处理线程就会逐个从队列中取出数据进行处理,通过队列的串行化保证顺序,避免复杂状态的逻辑维护。这就是这里的多线程的文件IO处理逻辑。
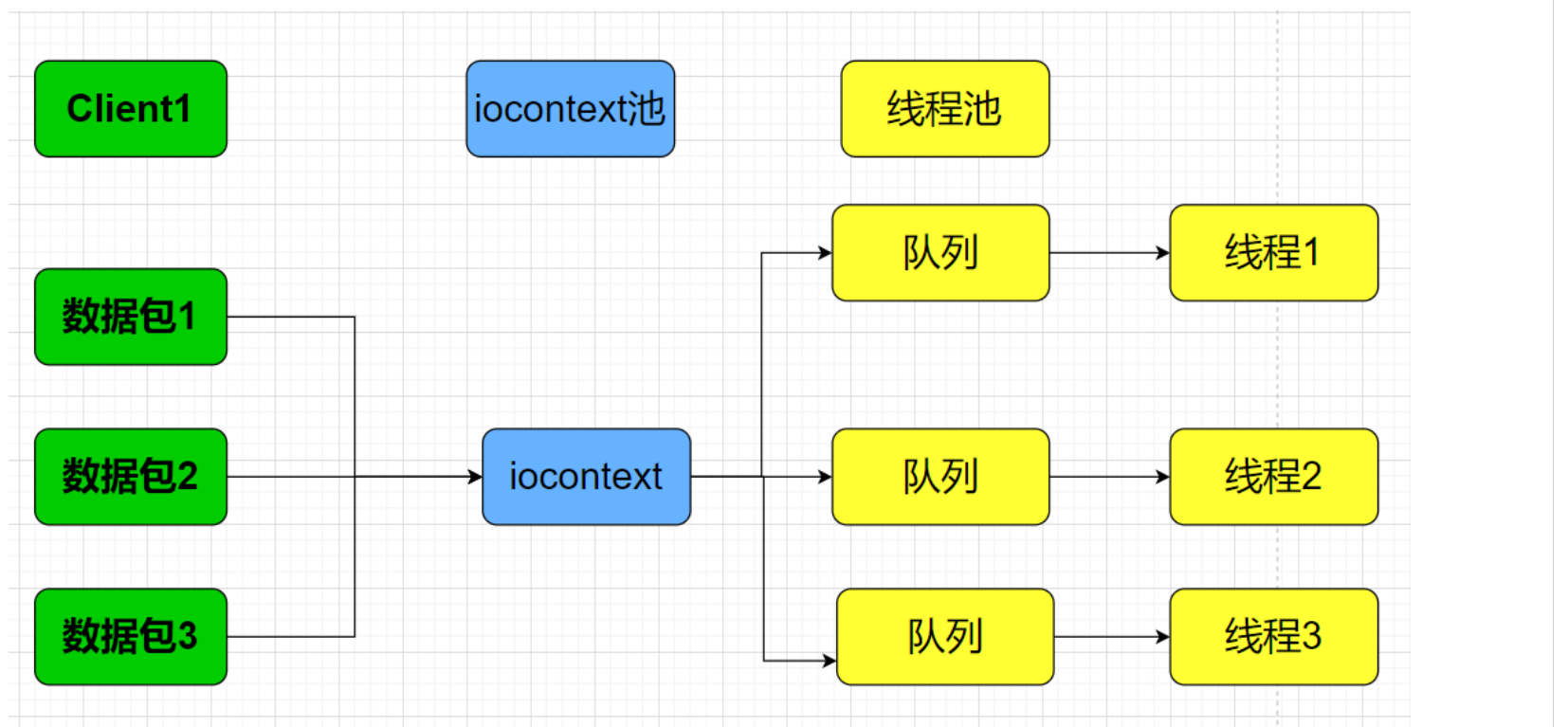
在这一版的基础上,还存在另外一半进行了进一步的解耦的逻辑,感兴趣可以自行分析一下,逻辑大致相同,只是为对应的底层的IO处理线程也引入了一层间接性。