字节序
在这里,我们对于机器的字节序进行一次简短的总结归纳,主要的是了解所谓的大小端字节序到底意味着什么。
对于大小端,你可以先将其简单的理解为一个机器中属于自己的一种对于字节的解析顺序。先从抽象的层面入手。我们先假设存在一个地址空间,如下。
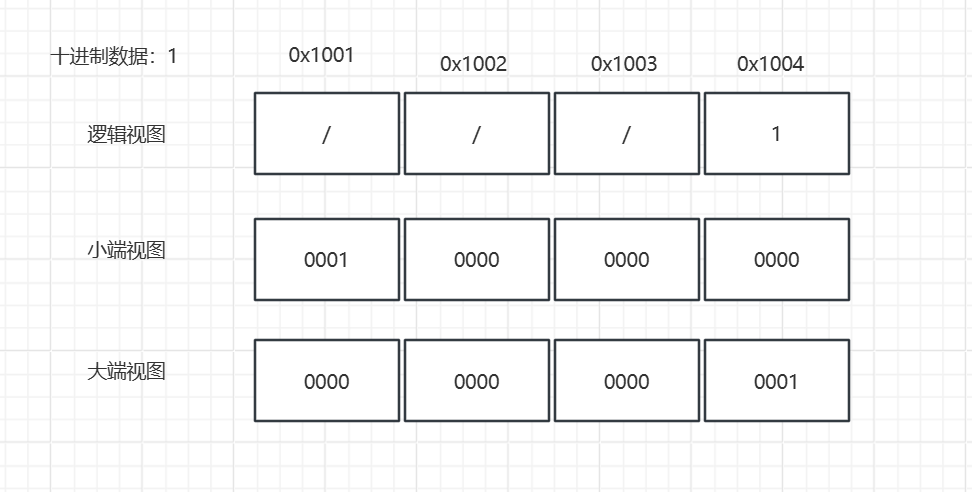
在外面的日常使用中,对于一个数字,我们有着自己的一个逻辑视图,即从左往右位数逐渐降低。或者说,我们默认相邻的俩侧左边高于右边。即逻辑视图中的情况。
那么对于大小端的数据排列呢?在此之前,我们需要先进行一下约束,我们约定抽象一个地址空间的地址为条带状的,并且从左往右对应的地址逐渐增加,或者说,代表的位置逐渐增加。即所谓的0x1001->0x1004的变化过程。通过这样,我们抽象出了一个地址空间的高低位,接下来我们将会使用这个相对位置的概念进行一些分析。可以看到,我们这里的小端序的数据排列中,我们将对应于1的数据放在了0x1001这个地址空间的低位处,而在大端中,我们则是放在了高位处。
我们先不去关心所谓的使用情况,我们先来分析一下这里的俩种字节序有着什么不同的抽象视图。我们先来抽象我们的逻辑视图中的数据摆放。众所周知,我们在写一个数据的时候会将所谓的个位十位百位从右往左逐个摆放,对应的数值也是逐渐增加。在这里我们可以抽象出:在逻辑视图中,我们将数据中代表的值比较小的放于低位中,将代表的数值比较大的数据,放于相对大的位置中。
那么,我们迁移这种抽象到对应的大小端的视图中。我们可以看到,在小端序的字节序中,我们将数据中代表的值比较小的数据字节块,放到了我们的低位地址处,而将数据中象征数值比较高的数据,放到了高位地址中,这里抽象出来的逻辑与逻辑视图是一致的。
但是,由于我们抽象中的地址空间是从左往右增加的,所以在这里看来我们的小端视图会与逻辑视图相反。但是如果我们将对应的增长顺序套到另外一方中,我们就能够获得一个完全相同的逻辑表示了。
同理,这里也能够清晰的看到,我们大端序中的代表低位的数据是被放置到了地址的高位中去,这种对于数据的组织形式是与逻辑视图截然相反的。
总的来说,我们总结一下对于一个字节序的判断思路。我们可以先将一块数据抽象开来,去获悉它底层的数据组织形式与我们所已知的是否相同。就比如,我们可以创建一个unsigned int符号,其中储存数值为1,请注意这里使用unsigned的原因。接着我们可以去尝试获取一个该符号的首地址,并进行解析操作,此时如果是小端序,那么其会输出的是1,否则输出的会是0。
那么,这里,如果你足够聪明,你应该注意到了一点在这种判断逻辑中需要注意的?停下来想一想……
那就是对于一个数据的地址,在大端序或者小端序的机器中,我们机器对应的寻址是否会存在不同?答案是不会的,简单来说,无论对于什么端的机器,其在内部对于一个变量的定位都是其所占据的地址片段中的低位地址,对于这块地址需要怎么进行解析,这一块会是在这之上的封装的操作所需要关注的事情。
接下来贴出一个检测的代码,有兴趣可以去写一下,不难。
1 |
|