储存管理
前情回顾
接下来,我将跟着15445的进度跳过中间的中级SQL和高级SQL和其他一些对于数据库的优化操作,直接跳到书籍的第三章节中来。正如15445在课程中所说的,这门课程主要是为了让我们了解一个数据库系统到底是什么,而不是了解数据库系统怎么来进行使用。
如下图

我其实在学习这个的时候遇到了一个问题,就是我学校的课程内容其实相对于15445来说存在比较大的出入,就比如,学校的课程目标在database system concepts中主要就是第一二部分的内容。但是15445的课程目标则是后面的第三部分的内容,从底层来进行分析一个DBMS。在我看来,你作为一个CSER,在这方面的选择其实不应该犹豫,毕竟相对来说,CMU已经是很多CSER所能接触到的最好的课程了,如果想要拥有一个更好的底子,跟着CMU的课程目标走无疑是更加能够提高个人的能力的,所以,拼命吧,不必要去学校偷懒。
CSER,Database Start!
先来看一个图,这个其实15445的课程大纲

该图中的左侧是15445整门课程大致的学习章目,此时我们已经进入Storage储存管理部分,右侧的层次架构是整个储存部分的基础管理结构,由下至上逐渐抽象,逐渐的远离硬件结构,在15445中则是从底层逐渐学起,逐渐架构起对于硬件与软件层次的认知。
数据储存
接下来我们来进行对于一个DBMS中数据的底层管理体系进行分析。
学过了CSAPP,其实不难知道数据在底层上都应该是储存在磁盘等非易失性储存器的,数据库中最主要的就是那些数据,因此这一点又需要额外重点注意。在这种架构下,DBMS确保了一个数据库的主要储存位置都位于非易失型储存器上。在现代的数据库使用中,由于在性能与损耗之间的平衡,对于需要使用的数据库数据,还是需要从非易失型储存器转移到主存中的,正如操作系统负责部分文件从外存往内存中的加载一样,DBMS负责数据库的数据在易失型和非易失型储存器之间的移动。
因此,接下来的学习中,我们的重点将会侧重于如果将一个DB中的数据安全的转移到主存中去,话不多说,启动。
储存架构
接下来看一个老朋友
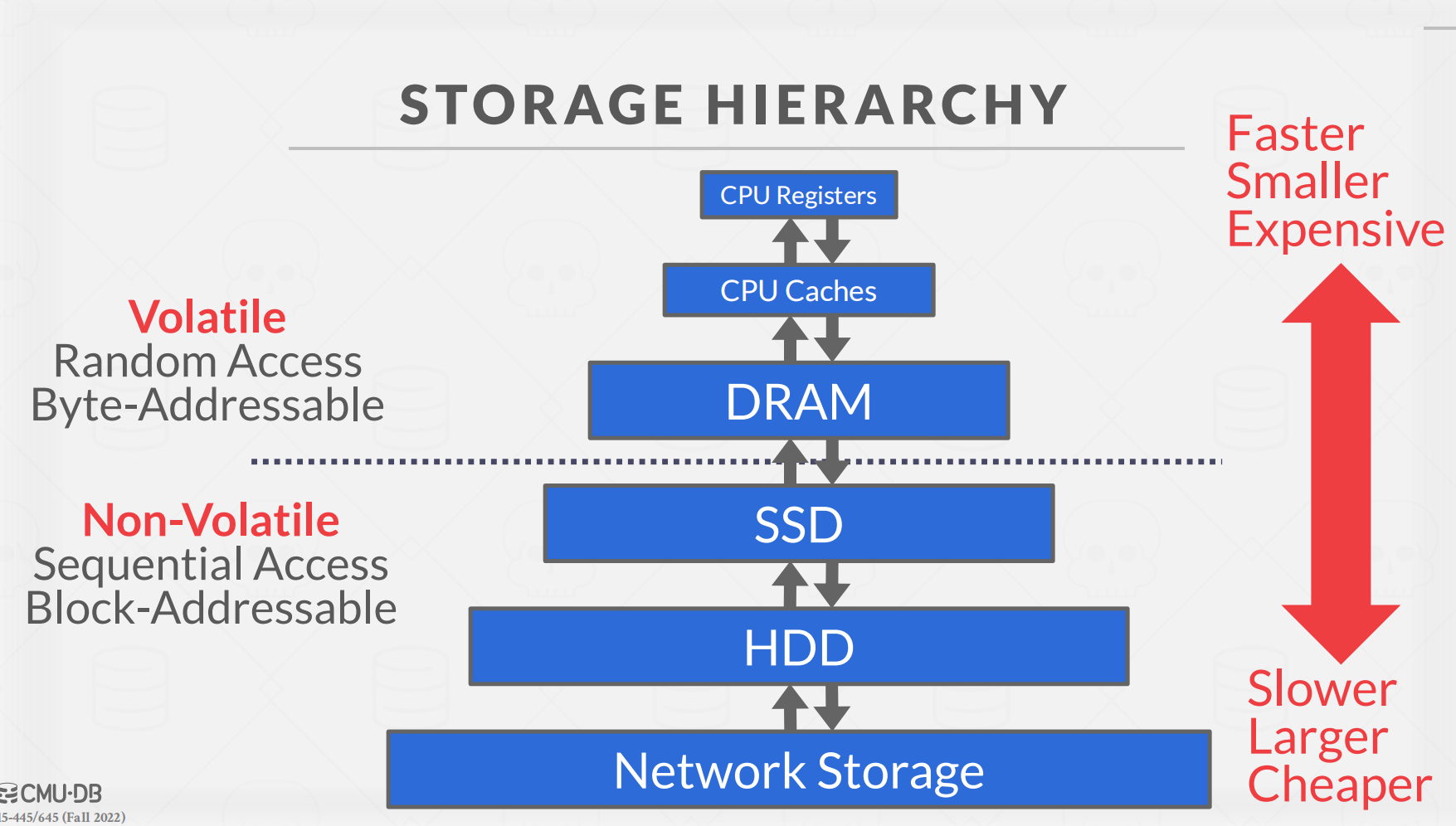
对于这个图中的内存架构,如果学过CSAPP中的储存模型,相似能够很快的理解。
这里主要对一些东西重复一下
- Volatile(易失型储存器):在易失型储存器中,储存器硬件上的内容可以按照字节来进行寻址,但是这种储存器一但断电其上面储存的信息将会在很短的一段时间内小时,不难长时间储存。
- Non-Volatile(非易失型储存器):一般来说,非易失型储存器并不能按照上面的通过字节来进行内容的读取,因为它实在是太慢了,使用按字节读取的损耗不能够弥补付出。但是这种储存器在断电后其上的信息仍然能够长时间储存。
在数据库的内存系统中,我们主要考虑的是在各个硬件架构之后,我们需要怎么去确保在数据的传输过程更安全,更有效率,话不多说,开始。

在non-volatile中,基本所有情况下对于数据的随机访问都是慢与顺序访问的,这样其实也很好理解,毕竟相对于顺序访问,随机访问通常意味着更多的磁头的移动和读取,这种硬件的移动和读取是我们所不喜欢的,这大大影响了数据读取的效率,那么一个DBMS就必须在这一块之上去下功夫。
最简单的一点,为了优化效率,我们在设计DBMS时,我们需要去选择哪些能够使得我们最后在读取/写入数据时能够顺序读取/写入数据的数据结构或者算法。就比如,我们在需要将主存中的数据写回到外存中时,去选择哪些能够顺序写入外存的储存页的方法,写出同理。
例如,在MySQL中,在往磁盘写入数据时,其通常是先将需要写入的数据先给以顺序写入的方式写入到一个缓存池中去,然后通知外界你这块数据已经成功被保存。但是实际上这块数据可能还没有被写入到外存中,只有当触发了缓存池中的写入限制时才会一次性写入到外存中,这次写入可能是随机写入的,但是我们不用对这个进行管理,因为这个是在后台进行的。
接下来来看一个美图
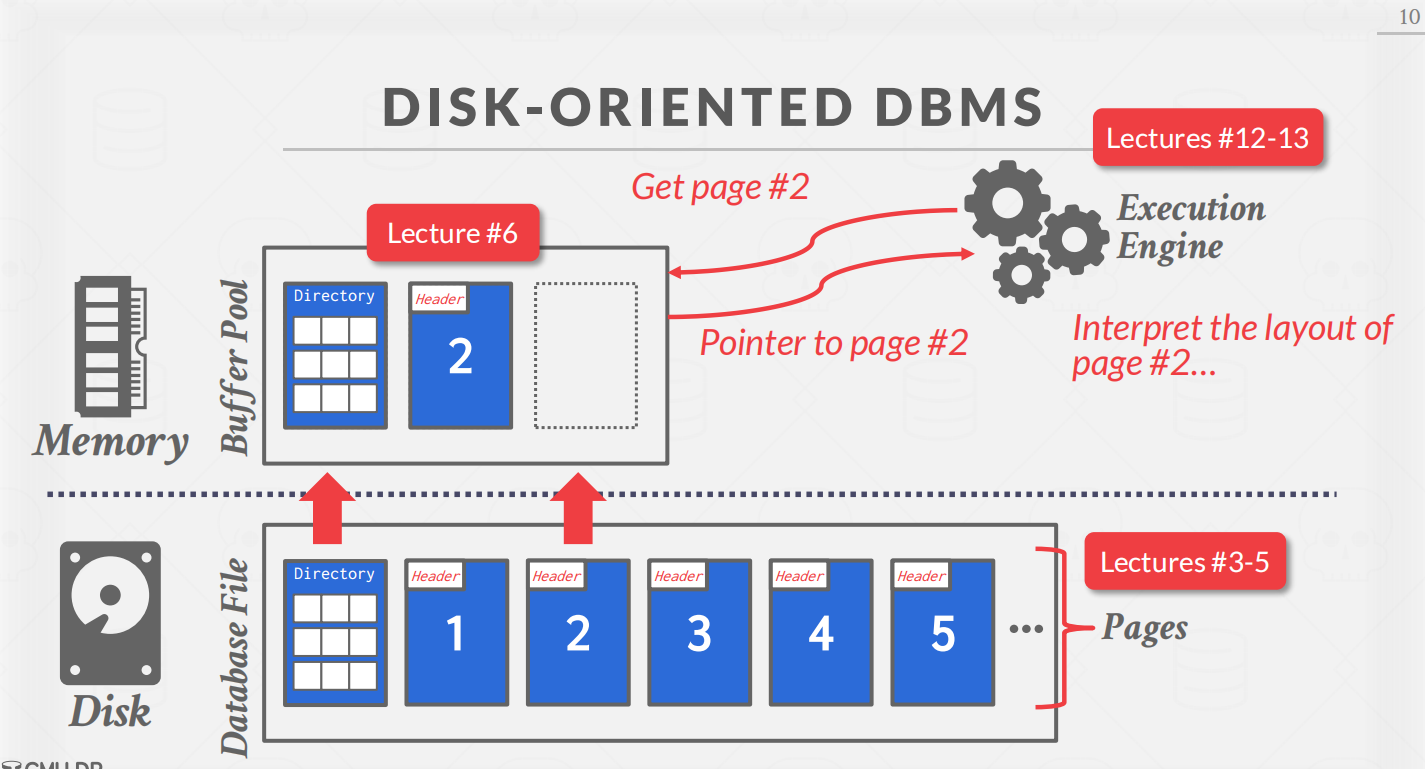
这个的图学过CSAPP的话,一眼过去基本就能猜测出对应的操作了,这里就不进行再分析了。
在DBMS中,上面那个过程对于disk上的内存页的调配很多程度上都是相对于OS独立实现的,那么,为什么呢,为什么要自己造轮子呢?(其实使用C++来写东西的人应该对于这个问题会有一个初步的自己的回答)
这一块不会进行分析,时间紧任务重,先赶进度先。在课间中对于这一点进行了这一块的较大篇幅的讲解,感兴趣可以去看一看。
文件储存

在DBMS中,对于数据库一般都是以文件的形式储存在disk上的,OS无法解析这些文件,只是知道这些文件的存在。并且,基本上每个DBMS都有自己一套的数据库的储存方法,很多DBMS的数据库文件都是无法互相解析的。部分DBMS例外。
需要注意的是,在15445中,其进行学习的储存基础的文件系统是OS的文件系统,对于哪些少数自己实现文件系统的,并不在课程讨论之内。

一个DBMS中一般会存在一个自己的storage manager用来管理自己的数据库文件,通过对manager进行特定的优化可以看到各个数据库之间的性能差距,但我们这里要学习的是他们的基本共性。
对于一个manager,其一般会将文件视为一系列的pages的集合,在文件中,其负责跟踪每个页在该文件中的位置已经跟踪每个页中存在的空闲位置。
PAGES
接下来我们来看到数据库文件的基本储存单位:pages。

对于一个pages来说,其内部一般是一系列的block的集合,在每个页中,其中包含了关于这个页中的一些信息,这个就像我们二进制文件中的那些前置信息一样,这些信息一般都是位于页的起始部分的,规定了页的一些基础属性,已经系列页的跳转位置,页内的块索引等等,碰到再说。
额外的,每个页拥有,也需要一个唯一且特殊的标识符来进行标识,这个由DBMS来设定和提供。
一般来说,在一个页中,该页只会储存一种类型的数据,就比如当储存一个表时,一般只会储存这个表的数据而不会混杂多个表的数据,当是索引页的时候,就不会去储存数据页。这种设计其实在CSAPP中也有一定的出现,优势页很明显,就是这样的设计能够减少页的切换,使得你要读取数据时,一般只需要再一个页内去读取就行,对应与磁头等的物理操作就会减少一些,提高了效率,对应的只是一些越来越廉价的外存的损耗,这是完全可以接受的。
同时,这种设计也使得在硬盘在遭受一些极端的外界因素而损毁时,我们能够尽可能的去读取剩余的数据(如果表头数据还在的话)。
有时我们会在页中去储存多余的元数据,这在一定程度上也是为了数据的恢复。

在计算机层面上,存在着多种pages,最底层的是Hardware Page,这种是最基本的硬件层面上的页,接着是OS Page,这种是OS定义的基本页,通常都是与Hardware Page相挂钩的,以前一般是与其一样的大小,在现在内存廉价后变大了许多,但在本门课中假设OS Pages跟Hardware Page的大小一致为4KB。再之后就是我们的Database Page,这个是建立在OS Pages上的,虽然DBMS不使用OS的文件系统,但是DBMS的文件读取读入,还是通过OS实现的,至于Database Pages的大小,这个每个DBMS一般都有自己的规定,如上右图。
我们这里需要对页的大小的选择进行一下分析,为什么不直接选择最大的页面而是有些选择较小的页面。这里需要考虑一个页的写回,当我们一个页的大小是16KB时,我们对其修改了一些数据后需要对其进行写回,那么此时OS需要做什么,OS需要把整个16KB大小的页面都给写回到disk中,假设我们只对于这个页面修改了1条数据,其在写回时仍需要把这个16KB大小的页面写回,这是十分浪费的,当然,较大的页面大小使得我们在这个页中去查询大量相同的数据时拥有更高的效率,所以我们需要平衡页面大小与查询性能之间的关系。
举例,当我们对于数据库操作是读密集型的时候,大页面会具有更大的优势,毕竟你可以在一个页面内去读取更多的数据,再需要时再丢弃这个页读取新页。而对于写密集型的时候,小页面具有更大的优势,因为写回时会浪费的页面大小空间会相对大页来说更少。
储存形式

在不同的DBMS中,其对于其自己的数据库文件中的页管理可能是不同的形式的。这里先来对于Heap File Organization来进行讨论,这是最常见的一种DBMS对于数据库文件中的页面管理方法。

对于堆文件架构的数据库文件来说,其中储存的页是无序的,或者说,其中的数据时按照插入顺序排序的,每个页面都有着自己独立的一个编号,通过这个编号,在需要查找某块数据时,通过数据对于的页编号能够索引到对应的块。
1 | Offset = Page# x PageSize; |

在一个DBMS当中,通常会存在一个特殊的索引页来进行对应数据库文件中的特定页的索引,通过这个索引页,可以索引到对应的页,但是需要注意的是,也只能索引到特定的页,至于对于也里面的数据内容,这不是索引页中需要了解的,是在索引到特定的页之后需要对其进行的解析等的操作。
在课程中,还对堆文件中的空闲页空间管理进行了一次demo的演示,在DBMS中,存在着一种能够跟踪储存一个表的系列页的空闲空间的方法。在演示的demo中,我们看到有时候我们往数据库中去插入对于的数据然后去查看插入后的对应的表的空闲空间,可能是与插入前一致的(猜测其实是被缓存了还没有插入,因此,没有触发对应的空闲空间的检测),但是如果此时使用DBMS自带的更新语句更新再查询,就会发现对应的页空闲空间产生了变化。接着还有当我们从表中去删除数据再去查看对应的空闲空间时,可以看到删除后的空闲空间发生了实时的变化。通过这个可以看到对于的DBMS的空闲页的更新机制。
需要注意的是,这里的空闲空间查询机制在一些程度上是相对独立的机制,或者这么说,只要你去查看了对应的表所使用的页的空闲空间,那么它所输出的结果就确实是现在在disk上的空闲空间大小,只是我们空闲空间管理器锁需要具备的基本功能。至于为什么我们插入数据后还是没有变化,想必你也有点头绪,就是因为此时这些插入的数据还是被缓存了,并没有被实时的写入到对应的disk中的文件中,因此此时查看磁盘中的文件空闲空间才会是插入之前的情况。至于删除这种操作后会有区别,想必就是进行了实时的更新了吧,这个应该取决于你DBMS的设计,如果设计的删除和插入一样会被缓存,那么这里的查询也应该会延后更新。不过这都不重要,因为我们已经理解了缓存会带来的空闲查询延后更新的这种影响。
PAGE格式
接下来看到PAGE的格式。众所周知啊,对于底层数据的文件,页,块等的组织,一般都会在对应区域的其实位置附上一些信息用于识别该块内存所有的一些信息。也就是所谓的头部。

在页的头部中,包含了这个页的大小和一些杂七杂八的信息,这里就不进行一个个深入了。
我们主要的是接下来的内容,一个页中是如何对其中的数据进行组织的,换句话说,一个页中是如何储存其的信息,对应的元组是怎么进行排列的。在接下来的讨论中,可以考虑十分友好的遵守了单一职责原则,在这里面我们暂时只需要考虑文件内部如何组织数据而不必去考虑外部给其带来的影响。
接下来看到一个问题:当我们要储存一个元组时,我们应该如何将这些元组放入到这些页面中,当我们想要从一个页中去查找一个元组,我们需要怎么去查找。
接下来看一种元组的储存形式

这是一个顺序储存,当我们需要插入元组的时候,分配器会为其分配一个特定的ID并查找空闲区域并进行插入,在只存在插入时这种架构不会存在什么问题,但是想想也是不可能的,最明显的,当你需要进行删除时,会发生什么呢。首先,你需要去将页内的元组的存在有效性被抹除,对应的内存块对于外界来说会是一个空闲的状态。那么,当此时我们需要插入时,由于顺序插入,查询到空闲且合理的位置就进行插入,那么这里就可能导致类似于 Tuple #1 Tuple #4 Tuple #3之类的元组顺序,这样的话对于外界来说,索引起来是非常麻烦的。
还存在一个问题,在这种内存架构下,如果你的元组大小的长度是一个可变的呢,就比如不同的邮箱通常存在着不同的长度,如果你想要去规定元组的大小为最大的长度,那么这里就会存在一个十分常见且不讨喜的问题。在一定时间的使用后,内存空间将会被严重碎片化,这是我们所不想看到的。
在种种这种顺序储存结构存在的缺陷的基础上,出现了另外的一种储存格式:槽页面
slotted pages
接下来看一下一种顺序存储的优化页面,槽页面。
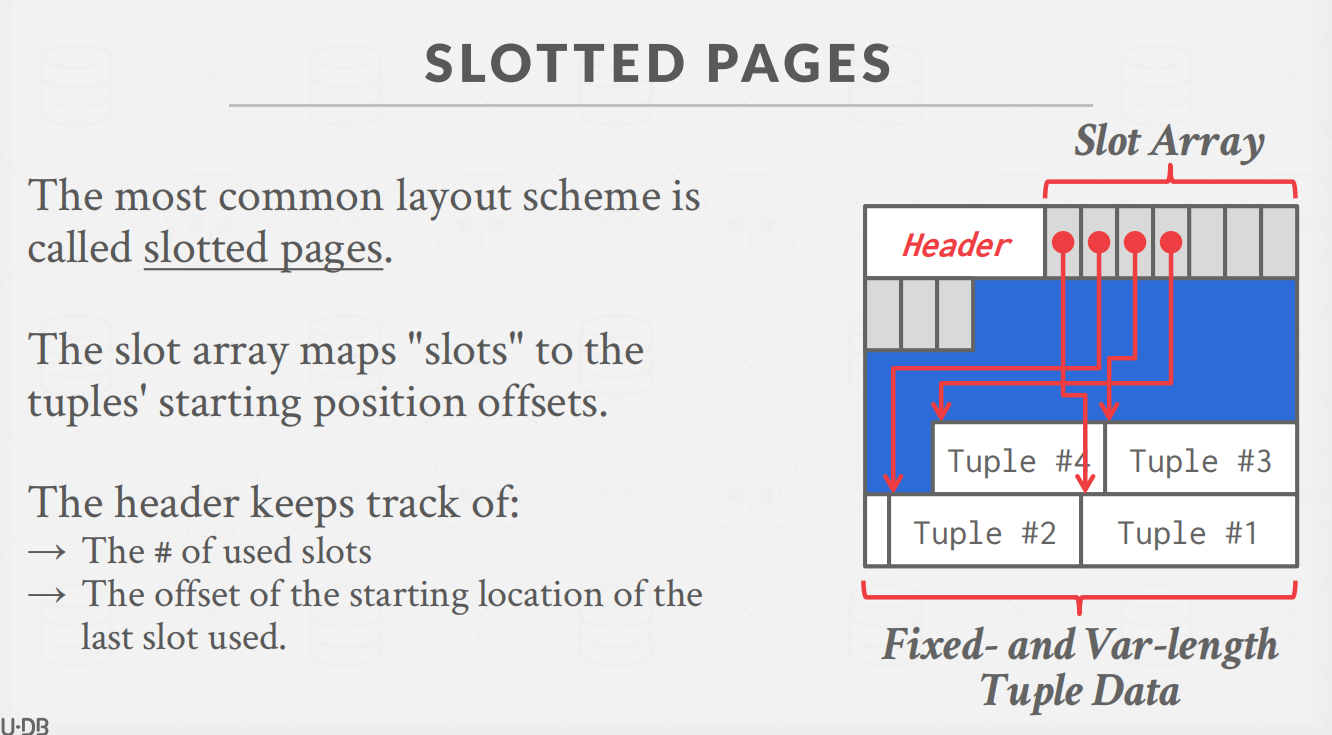
在槽页面中,出现了额外的一种结构(槽数组)来对页内的元组进行管理。在这种架构下,元组的储存位置与数据进一步的分离了。可以说,这种架构下的槽数组的每个元素与每个元组之间,类似于一种映射的关系。通过槽数组中的数据,可以直接去定位到对应的元组位置,这种分离使得在元组的管理上更加的灵活。
需要注意的是,但我们进行元组的插入时,同时会有元组数据的生长和槽数组的生长,当俩个不同属性的内存块触碰到一起时,这个页会被视为满并且不再允许插入。当然可能碰到一种情况,就是你要插入一个元组。但是表中的剩余空间不够插入,这种情况我们会在下一节课程中进行分析。
对于元组来说,其的添加删除其实还是跟之前很相似,都是查询到一块空闲区域时进行插入,但是这种架构下的元组相较于顺序存储具有更强的变长能力。当插入不同长度的元组时的操作并无不同,猜测在槽数组中,每个元素都包含了一系列元组的信息,其中就包括了对应元组的长度。同时,删除时的操作其实也跟之前很相似,这里是将元组对于的槽数组元素的可用标志位给置否(类似于语言中内存分配器的实现)。其实这种结构下的内存分配,与各个语言中的内存分配器很相似,所以其实没有什么新奇的地方。
与内存分配器相同的是,在这种架构下的页结构对于碎片化的空闲空间在一定的时机中也可能触发合并操作,比如可能挪动部分的元组位置来进行合并碎片小块来提供一个大块的操作。总总这些,其实跟内存分配器的思路很相似,这里不再进行赘诉。
让我们来对于这种架构下的几个我比较在意优势做几点分析:
- 在这种架构下,一个页对于外界来说是未知的,换句话说,外界无法知道一个页内到底发生了什么,但是,外界可以通过对页提出一定的请求来获取对应的数据。即进行了外界与页内部的解耦,是数据的查找不必要依赖于外界的实现
- 在页内,内存管理方面也更加灵活,当需要进行一些元组的移动时,需要更改的地方不会像之前的顺序储存一样牵一发而动全身,只需要修改对应元组的槽数组的对应元素属性即可,大大减少了内存管理方面的麻烦。
- 同时使得各个模块可以专注于自己的功能,就比如内部的元组的移动,其所需要负责的只有对应的数组元素的修改更新通知,不会需要再往上层去查询去修改对应的代码。
总结
槽页面架构通过引入槽数组,成功地将元组的管理与数据的实际存储位置分离,使得插入、删除操作更加高效,并且具备了更强的可变长度支持。同时,槽数组的设计与内存分配器非常相似,通过标记、合并等方式有效管理内存碎片化问题,提升了存储空间的利用率和系统的整体性能。