Modern SQL
数据库系统

需要注意的是,一个数据库系统中是存在着多个组件的,比较简单的理解的话。一个系统首先需要包括几个用来进行操作的语言。
其中包括的几种语言有:**数据操作语言(DML),数据定义语言(DDL),数据控制语言(DCL)**。
对于这三种语言,我们在这里进行一个相对简单的接触即可。
- 数据操作语言(DML):用于操作数据库中的数据。常见的DML命令包括
SELECT、INSERT、UPDATE和DELETE,这些命令帮助我们从数据库中查询数据、插入新数据、修改现有数据或删除数据。 - 数据定义语言(DDL):用于定义和管理数据库中的结构,例如表、视图、索引等。常见的DDL命令包括
CREATE、ALTER、DROP等,用来创建、修改或删除数据库的结构。 - 数据控制语言(DCL):用于控制数据库的访问权限。常见的DCL命令有
GRANT(授予权限)和REVOKE(撤销权限),它们允许数据库管理员控制哪些用户可以访问哪些数据。
粗略来看,DML就是对于数据库中存在的数据可以进行的一些查询,修改等操作。是直接作用于数据层面的。而DDL是对于数据库中数据的架构的规划语言,是作用于结构层面的。而DCL直观来看其实就是对于来自不同请求的权限控制。
加下来将会进入一些聚合操作,查询操作等的了解
聚合函数
在SQL中,存在着一些相对特殊的函数,这些函数以一系列的数据为输入,然后输出一个值。这些函数一般被称为聚合函数。

上图中就是一些比较常用的聚合函数,函数的功能也比较简单,这里就没必要进行深入,等之后进入一些更加复杂的应用场景时可以来回顾一下。简单了解下这几个函数的功能即可。
- AVL(col)根据输入的值去计算平均值后返回,需要输入值能够被计算。
- MIN(col)根据输入的值去查找最小值并返回该值
- MAX(col)根据输入的值去查找最大值并返回该值
- SUM(col)根据输入的值去计算总和并返回
- COUNT(col)根据输入的值去返回这些值中非空值的个数
在进入下一步之前,我们默认你已经了解最基本的数据库查询操作,即一个由selete子句,from子句,where子句组成的基本查询操作,如果不知道,还是先回去看书吧。
注意事项
聚合函数还存在一些使用上的限制,或者说,一些特性需要了解

使用位置
聚合函数只能在select子句中进行使用,并且使用聚合函数后select子句输出的内容将会是对应的聚合函数功能。
1 | SELECT COUNT(1+1+1) AS cnt |
额外注意一下,这里的as关键字起到一个名称替换的效果。这里的like关键字起到字符串匹配的一个效果,具体的等下再讲。
去除重复项
部分聚合函数也可以使用关键字distinct来去除重复项

使用方式也很简单,就是在对于的聚合函数里面加上distinct关键字,如上图中的使用。
额外需要注意的是,正如上图中指出,不是所有的函数都支持distinct关键字的,毕竟有时候distinct关键字的含义与一些聚合函数的功能之间存在一些歧义,应该是在设计上就进行了这些的摒弃。
使用限制
聚合函数中使用的参数也存在着一些限制。官方来说
出现在select子句中但没有被聚合的属性只能是出现在group by子句中的属性。换句话说,任何没有出现在group by子句中的属性如果出现在select子句中,那么它只能作为聚合函数的参数作为使用。
这句话应该配合实例来辅助理解。
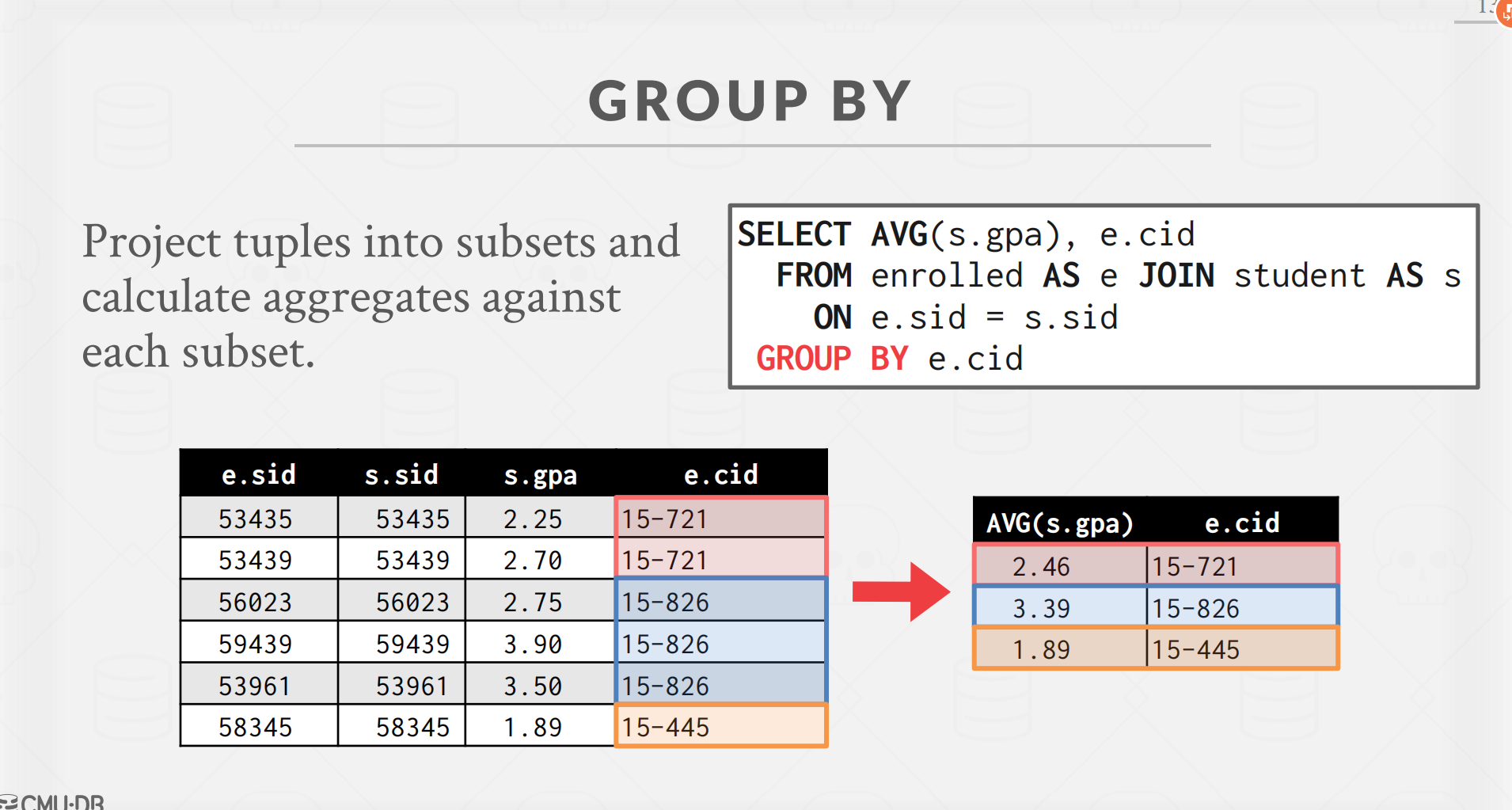
首先,我们需要明白一个group by子句所能带来的作用。通过一个group子句,数据库可以吧对应的表根据子句中的元素列出为多组,其中每一组都是对应的子句中出现的元素。
然后我们来看到select子句所能带来的作用,该子句能够将对应的表中的数据进行操作来输出一个新表。那么,我们前面已经通过group by子句将这些元组分为若干个组了,此时我们如果想要加上一个没有任何限制的元素在select子句中,那会出现什么。很自然想到的是,这个将会出现一系列的元素没有一个对应的元组给它匹配到,而这个是我们所不想看到的。这也是这么一种设计的原因。
接下来我们再来看到这种设计中使用聚合函数将会出现的结果。当我们进行了group by子句进行分组后,我们如果想要正确的输出一个表,我们需要为每个分组后的新元组都提供对于的元素进行构建。也就是说,我们的select操作应该是基于分组后的各个子元组集合的。这也是为什么对于那些个没有出现在group by子句中的元素需要我们去进行聚合函数的原因,只有通过聚合,我们才能通过一组值来输出一个值用于一个元组的构建。
也就是说,还是跟前面一样,我们的select子句中就是最后的新表中的目标元素的集合。一个查询语句中如果出现了group by子句,那么对应的select子句中没有使用聚合函数的元素就是我们分组的依据,其他的使用聚合函数的则是我们目标新组中需要的元素。
我很喜欢GPT对于我这段话总结出来的几句话。

Having子句
生效时机
接下来看到一个与聚合函数具有较强关联的一个语句,having子句。这个子句与where子句有点相像。都是对于已有元组的一种条件筛选。
在之前的学习中,我们了解到where子句其实是对于整个查询操作中原始表的一个过滤。这个过滤操作是紧跟在from子句之后的。在这个过滤之后才会去进行接下来的一系列查询操作子句的进行。那么,这里就存在一个问题了,由于这个where语句的时机,所以我们其实是无法使用这个where子句去进行分组后的过滤的。毕竟,这个group by子句发生的时机是位于where子句之后的。
但是对于这种分组后过滤的操作,这种操作映射到现实生活中是非常常见的。就比如,你希望知道一个初中学校7年级中平均分最高的班级。那么此时只有where子句是无法满足我们的要求的。此时设计者就引入了一个新的子句,having子句。这个子句的功能与where子句基本相同,区分他俩的主要特征就是俩者发生的时机。正如前文所说,一个having子句能够对于分组后的结果在进行筛选。不难推测having子句的发生时机就是位于group by子句之后。
举例
假设你有一个销售表 sales,包含 region(地区)和 sales_amount(销售额)两列。如果你想按 region 分组并计算每个地区的总销售额,同时只返回总销售额大于 1000 的地区,查询可以这样写:
1 | SELECT region, SUM(sales_amount) AS total_sales |
在这个例子中:
GROUP BY region将数据按地区分组。SUM(sales_amount)计算每个地区的总销售额。HAVING SUM(sales_amount) > 1000对每个分组的总销售额进行筛选,只保留销售额大于 1000 的地区。
简单归纳
HAVING 子句:用来过滤 分组后的结果(在 GROUP BY 后),它针对分组后的数据进行筛选。换句话说,HAVING 过滤的是每个分组的聚合结果。
在实际应用中,我们可以看到事实上基本全部的having子句中都是聚合函数的一些条件限制,这个其实很好理解。毕竟前面我们已经说过了having子句就是用来进行分组后的条件筛选的,而分组后的分组依赖项本来就不应该被用来进行筛选,我们应该筛选的是每个分组的对应属性,体现在查询语句中的就是对应的select子句中使用聚合函数中的系列项。因此,在Having子句中看到这些个聚合函数也就不奇怪,或者说,理所应当了。
特别需要注意一点,对于having子句来说,其的执行顺序是位于select子句之后的。我们可以看到在上面的示例中我们在select子句中去对于sales_amount进行了一个as别名的替换。但是我们在having子句中没有进行使用,这个其实也很好理解。毕竟这个其实就是对于执行顺序的一个应用。此时的别名对于子句还是不可见的,因此自然无法使用。
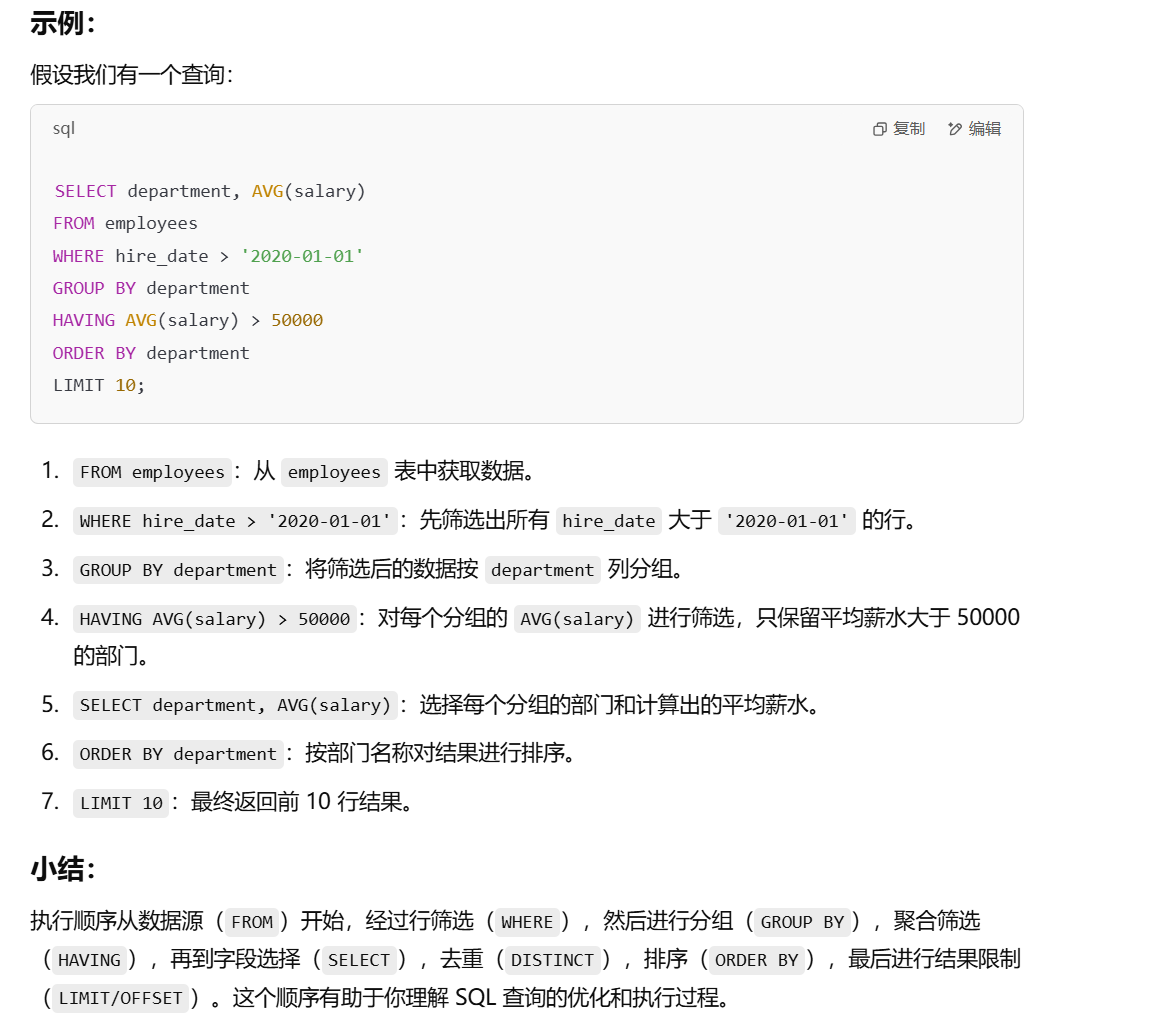
接下来贴一个查询语句中各个语句的执行顺序图


未完待续,由于篇幅过长,分割放送,下一部分看字符串操作。